
|
http://bit.ly/2Hrvw5C
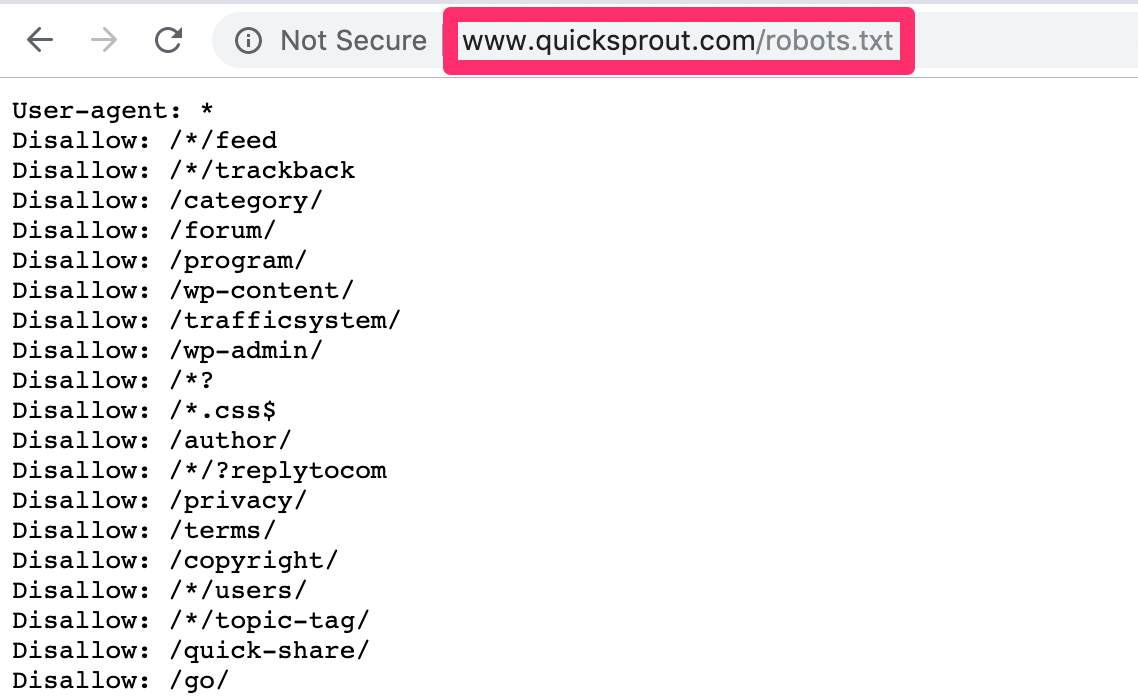
How to Optimize Your Robots.txt File http://bit.ly/2Q5S5kv SEO goes far and beyond keyword research and building backlinks. There is also a technical side of SEO that will largely impact your search ranking. This is an area where your robots.txt file will become a factor. In my experience, most people aren’t too familiar with robots.txt files and don’t know where to begin. That’s what inspired me to create this guide. Let’s start with the basics. What exactly is a robots.txt file? When a search engine bot is crawling a website, it uses the robots.txt file to determine what parts of the site need to be indexed. Sitemaps are hosted in your root folder and in the robots.txt file. You create a sitemap to make it easier for search engines to index your content. Think of your robots.txt file like a guide or instruction manual for bots. It’s a guide that has rules that they need to follow. These rules will tell crawlers what they’re allowed to view (like the pages on your sitemap) and what parts of your site are restricted. If your robots.txt file isn’t optimized properly, it can cause major SEO problems for your website. That’s why it’s important for you to understand exactly how this works and what you need to do to ensure that this technical component of your website is helping you, as opposed to hurting you. Find your robots.txt fileBefore you do anything, the first step is verifying that you have a robots.txt file to begin with. Some of you probably never came here before. The easiest way to see if your site already has one is by putting your website’s URL into a web browser, followed by /robots.txt. Here’s what it looks like for Quick Sprout.
When you do this, one of three things will happen.
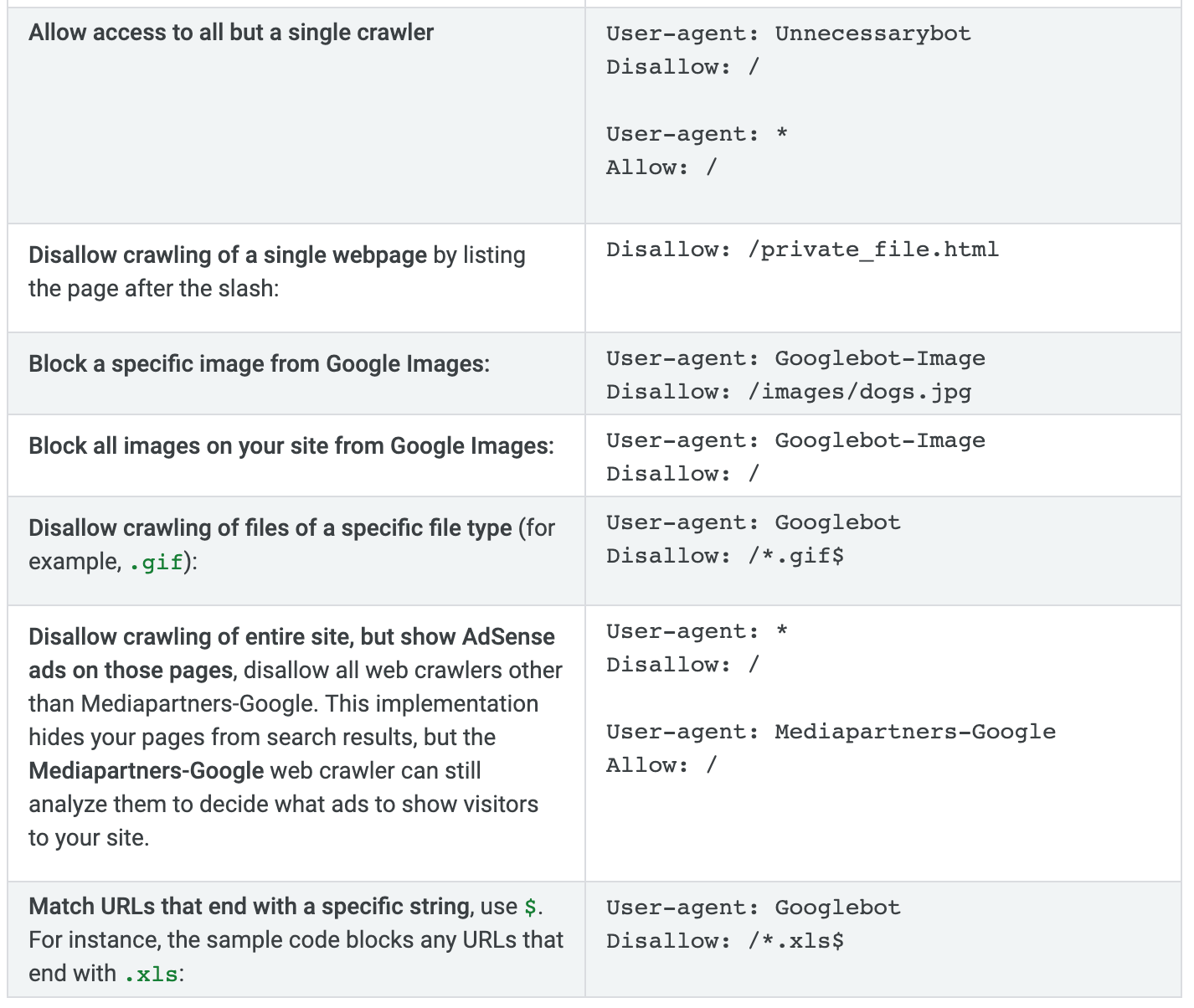
Most of you will likely fall into the top two scenarios. You shouldn’t get a 404 error because the majority of websites will have a robots.txt file setup by default when the site was created. Those default settings should still be there if you’ve never made any changes. To create or edit this file, just navigate to the root folder of your website. Modify your robots.txt contentFor the most part, you normally don’t want to mess around with this too much. It’s not something that you’re going to be altering on a frequent basis. The only reason why you would want to add something to your robots.txt file is if there are certain pages on your website that you don’t want bots to crawl and index. You need to get familiar with the syntax used for commands. So open up a plain text editor to write the syntax. I’ll cover the syntax that’s most commonly used. First, you need to identify the crawlers. This is referred to as the User-agent. User-agent: * This syntax above refers to all search engine crawlers (Google, Yahoo, Bing, etc.) User-agent: Googlebot As the name implies, this value is speaking directly to Google’s crawlers. After you identify the crawler, you can allow or disallow content on your site. Here’s an example that we saw earlier in the Quick Sprout robots.txt file. User-agent: * Disallow: /wp-content/ This page is used for our administrative backend for WordPress. So this command tells all crawlers (User-agent: *) not to crawl that page. There’s no reason for the bots to waste time crawling that. So let’s say you want to tell all bots not to crawl this specific page on your website. http://bit.ly/2w1An8s The syntax would look like this: User-agent: * Disallow: /samplepage1/ Here’s another example: Disallow: /*.gif$ This would block a specific file type (in this case .gif). You can refer to this chart from Google for more common rules and examples.
The concept is very straightforward. If you want to disallow pages, files, or content on your site from all crawlers (or specific crawlers) then you just need to find the proper syntax command and add it to your plain text editor. Once you’ve finished writing the commands, simply copy and paste that into your robots.txt file. Why the robots.txt file needs to be optimizedI know what some of you are thinking. Why in the world would I want to mess around with any of this? Here’s what you need to understand. The purpose of your robots.txt file isn’t to completely block pages or site content from a search engine. Instead, you’re just trying to maximize the efficiency of their crawl budgets. All you’re doing is telling the bots that they don’t need to crawl pages that aren’t made for the public. Here’s a summary of how Google’s crawl budget works. It’s broken down into two parts:
The crawl rate limit represents how many connections a crawler can make to any given site. This also includes the amount of time between fetches. Websites that respond quickly have a higher crawl rate limit, which means they can have more connections with the bot. On the other hand, sites that slow down as the result of crawling will not be crawled as frequently. Sites are also crawled based on demand. This means that popular websites are crawled on a more frequent basis. On the flip side, sites that aren’t popular or updated frequently won’t be crawled as often, even if the crawl rate limit has not been met. By optimizing your robots.txt file, you’re making the job of the crawlers much easier. According to Google, these are some examples of elements that affect crawl budgets:
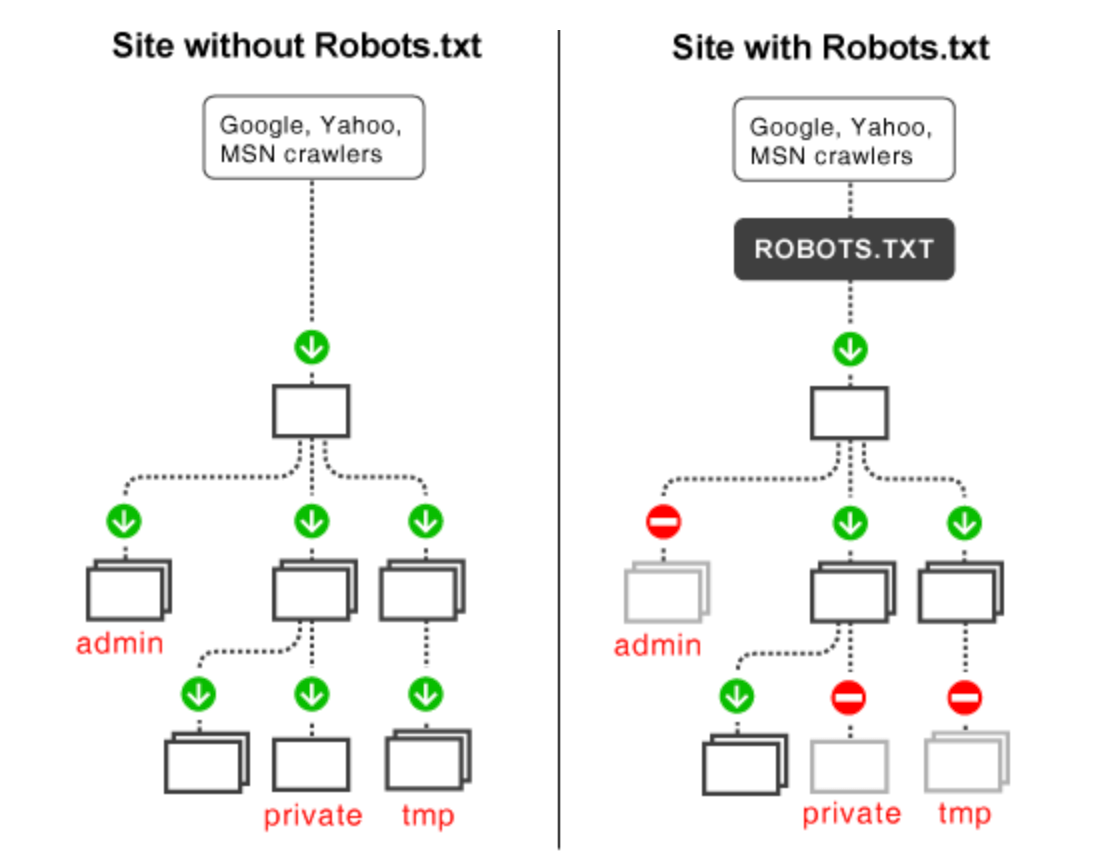
By using the robots.txt file to disallow this type of content from crawlers, it ensures that they spend more time discovering and indexing the top content on your website. Here’s a visual comparison of sites with and without an optimized robots.txt file.
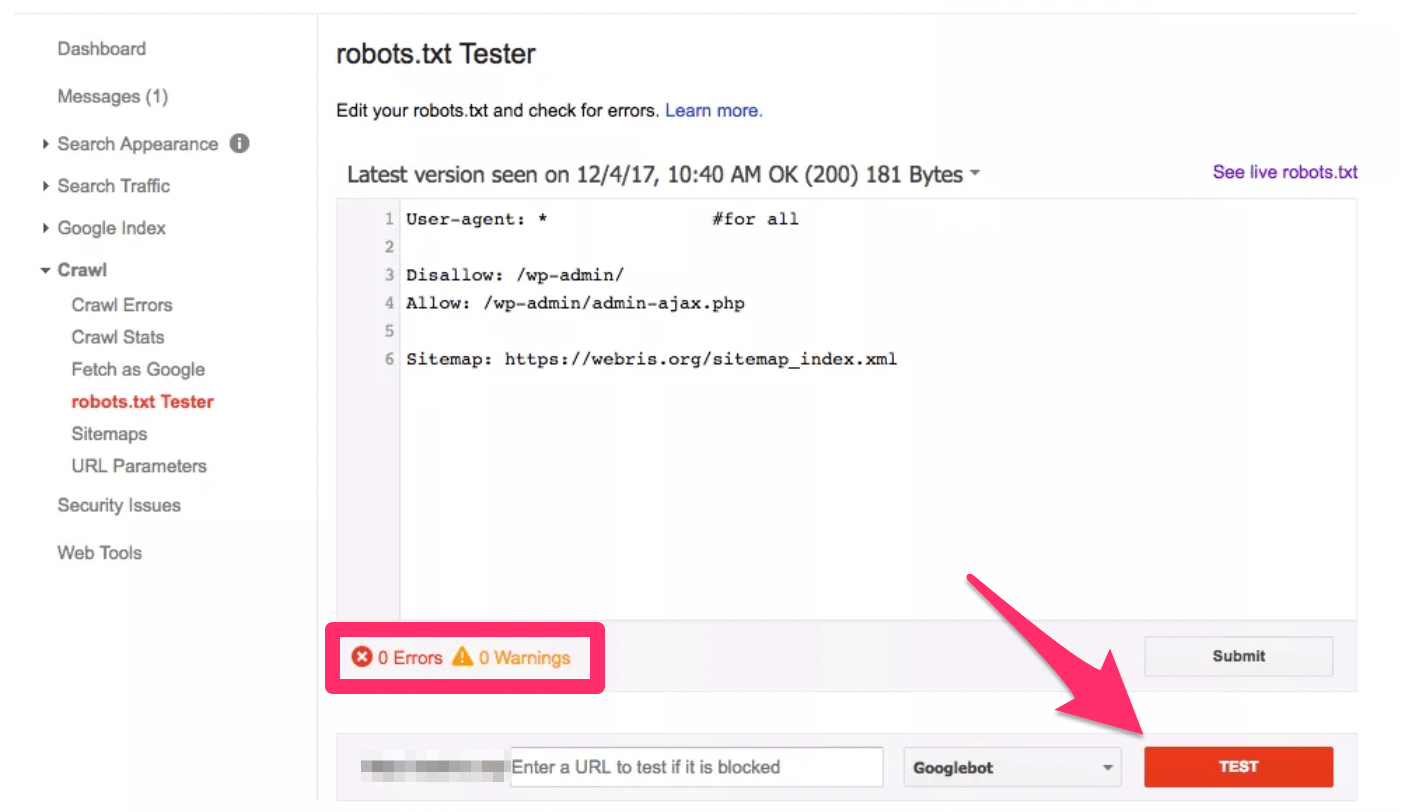
A search engine crawler will spend more time, and therefore more of the crawl budget, on the left website. But the site on the right ensures that only the top content is being crawled. Here’s a scenario where you’d want to take advantage of the robots.txt file. As I’m sure you know, duplicate content is harmful to SEO. But there are certain times when it’s necessary to have on your website. For example, some of you might have printer-friendly versions of specific pages. That’s duplicate content. So you can tell bots not to crawl that printer-friendly page by optimizing your robots.txt syntax. Testing your robots.txt fileOnce you’ve found, modified, and optimized your robots.txt file, it’s time to test everything to make sure that it’s working properly. In order to do this, you’ll need to sign into your Google Webmasters account. Navigate to “crawl” from your dashboard.
This will expand the menu. Once expanded, you’re going to look for the “robots.txt Tester” option.
Then simply click the “test” button in the bottom right corner of the screen.
If there are any problems, you can just edit the syntax directly in the tester. Continue running the tests until everything is smooth. Be aware that changes made in the tester do not get saved to your website. So you’ll need to make sure you copy and paste any changes into your actual robots.txt file. It’s also worth noting that this tool is only for testing Google bots and crawlers. It won’t be able to predict how other search engines will read your robots.txt file. Considering that Google controls 89.95% of the global search engine market share, I don’t think you need to run these tests using any other tools. But I’ll leave that decision up to you. Robots.txt best practicesYour robots.txt file needs to be named “robots.txt” in order to be found. It’s case-sensitive, meaning Robots.txt or robots.TXT would not be acceptable. The robots.txt file must always be in the root folder of your website in a top-level directory of the host. Anyone can see your robots.txt file. All they need to do is type in the name of your website URL with /robots.txt after the root domain to view it. So don’t use this to be sneaky or deceptive, since it’s essentially public information. For the most part, I wouldn’t recommend making specific rules for different search engine crawlers. I can’t see the benefit of having a certain set of rules for Google, and another set of rules for Bing. It’s much less confusing if your rules apply to all user-agents. Adding a disallow syntax to your robots.txt file won’t prevent that page from being indexed. Instead, you’d have to use a noindex tag. Search engine crawlers are extremely advanced. They essentially view your website content the same way that a real person would. So if your website uses CSS and JS to function, you should not block those folders in your robots.txt file. It will be a major SEO mistake if crawlers can’t see a functioning version of your website. If you want your robots.txt file to be recognized immediately after it’s been updated, submit it directly to Google, rather than waiting for your website to get crawled. Link equity cannot be passed from blocked pages to link destinations. This means that links on pages that are disallowed will be considered nofollow. So some links won’t be indexed unless they’re on other pages that are accessible by search engines. The robots.txt file is not a substitute for blocking private user data and other sensitive information from showing up in your SERPs. As I said before, disallowed pages can still be indexed. So you’ll still need to make sure that these pages are password protected and use a noindex meta directive. Sitemaps should be placed at the bottom of your robots.txt file. ConclusionThat was your crash-course on everything you need to know about robots.txt files. I know that lots of this information was a little technical, but don’t let that intimidate you. The basic concepts and applications of your robots.txt are fairly easy to understand. Remember, this isn’t something that you’ll want to modify too frequently. It’s also extremely important that you test everything out before you save the changes. Make sure that you double and triple-check everything. One error could cause a search engine to stop crawling your site altogether. This would be devastating to your SEO position. So only make changes that are absolutely necessary. When optimized correctly, your website will be crawled efficiently by Google’s crawl budget. This increases the chances that your top content will be noticed, indexed, and ranked accordingly. Social Media via Quick Sprout http://bit.ly/UU7LJr May 17, 2019 at 09:31AM
0 Comments
Leave a Reply. |
�
Amazing WeightLoss Categories
All
Archives
November 2020
|
 RSS Feed
RSS Feed
