
|
https://ift.tt/35RvFva
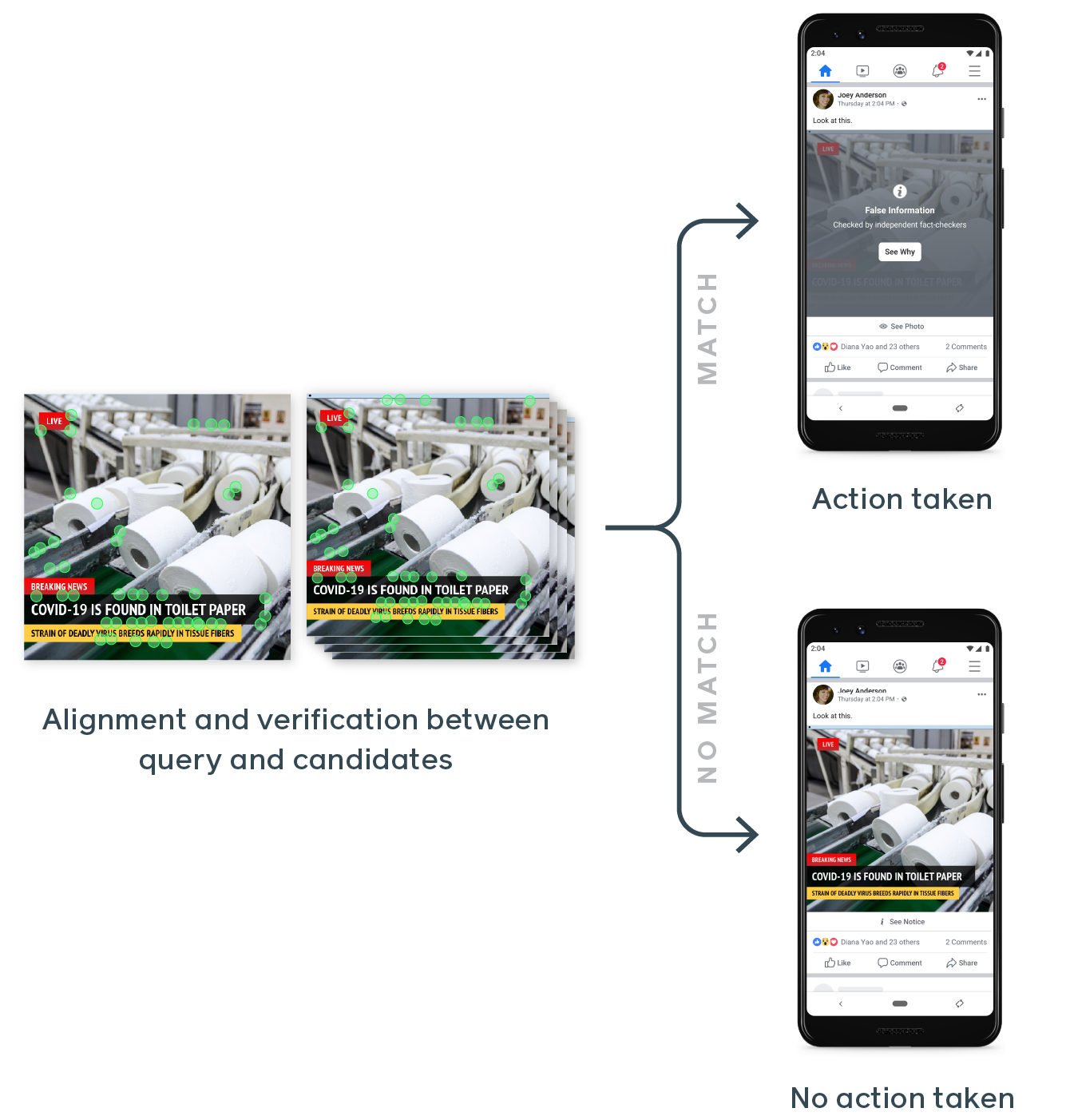
Facebook upgrades its AI to better tackle COVID-19 misinformation and hate speech https://ift.tt/3cq1cXq Facebook’s AI tools are the only thing standing between its users and the growing onslaught of hate and misinformation the platform is experiencing. The company’s researchers have cooked up a few new capabilities for the systems that keep the adversary at bay, identifying COVID-19-related misinformation and hateful speech disguised as memes. Detecting and removing misinformation relating to the virus is obviously a priority right now, as Facebook and other social media become breeding grounds not just for ordinary speculation and discussion, but malicious interference by organized campaigns aiming to sow discord and spread pseudoscience. “We have seen a huge change in behavior across the site because of COVID-19, a huge increase in misinformation that we consider dangerous,” said Facebook CTO Mike Schroepfer in a call with press earlier today. The company contracts with dozens of fact-checking organizations around the world, but — leaving aside the question of how effective the collaborations really are — misinformation has a way of quickly mutating, making taking down even a single image or link a complex affair. Take a look at the three example images below, for instance: An unsophisticated computer vision algorithm would either rate these as completely different images due to those small changes (they result in different hashes) or all the same due to overwhelming visual similarity. Of course we see the differences right away, but training an algorithm to do that reliably is very difficult. And the way things spread on Facebook, you might end up with thousands of variations rather than a handful. “What we want to be able to do is detect those things as being identical because they are, to a person, the same thing,” said Schroepfer. “Our previous systems were very accurate, but they were very fragile and brittle to even very small changes. If you change a small number of pixels, we were too nervous that it was different, and so we would mark it as different and not take it down. What we did here over the last two and a half years is build a neural net-based similarity detector that allowed us to better catch a wider variety of these variants again at very high accuracy.” Fortunately analyzing images at those scales is a specialty of Facebook’s. The infrastructure is there for comparing photos and searching for features like faces and less desirable things; it just needed to be taught what to look for. The result — from years of work, it should be said — is SimSearchNet, a system dedicated to finding and analyzing near-duplicates of a given image by close inspection of their most salient features (which may not be at all what you or I would notice).
SimSearchNet is currently inspecting every image uploaded to Instagram and Facebook — billions a day. The system is also monitoring Facebook Marketplace, where people trying to skirt the rules will upload the same image of an item for sale (say, an N95 face mask) but slightly edited to avoid being flagged by the system as not allowed. With the new system, the similarities between recolored or otherwise edited photos are noted and the sale stopped. Hateful memes and ambiguous skunksAnother issue Facebook has been dealing with is hate speech — and its more loosely defined sibling hateful speech. One area that has proven especially difficult for automated systems, however, is memes. The problem is that the meaning of these posts often results from an interplay between the image and the text. Words that would be perfectly appropriate or ambiguous on their own have their meaning clarified by the image on which they appear. Not only that, but there’s an endless number of variations in images or phrasings that can subtly change (or not change) the resulting meaning. See below: 
To be clear, these are toned-down “mean memes,” not the kind of truly hateful ones often found on Facebook. Each individual piece of the puzzle is fine in some contexts, insulting in others. How can a machine learning system learn to tell what’s good and what’s bad? This “multimodal hate speech” is a non-trivial problem because of the way AI works. We’ve built systems to understand language, and to classify images, but how those two things relate is not so simple a problem. The Facebook researchers note that there is “surprisingly little” research on the topic, so theirs is more an exploratory mission than a solution. The technique they arrived at had several steps. First, they had humans annotate a large collection of meme-type images as hateful or not, creating the Hateful Memes data set. Next, a machine learning system was trained on this data, but with a crucial difference from existing ones. Almost all such image analysis algorithms, when presented with text and an image at the same time, will classify the one, then the other, then attempt to relate the two together. But that has the aforementioned weakness that, independent of context, the text and images of hateful memes may be totally benign. Facebook’s system combines the information from text and image earlier in the pipeline, in what it calls “early fusion,” to differentiate it from the traditional “late fusion” approach. This is more akin to how people do it — looking at all the components of a piece of media before evaluating its meaning or tone. Right now the resultant algorithms aren’t ready for deployment at large — at around 65-70% overall accuracy, though Schroepfer cautioned that the team uses “the hardest of the hard problems” to evaluate efficacy. Some multimodal hate speech will be trivial to flag as such, while some is difficult even for humans to gauge. To help advance the art, Facebook is running a “Hateful Memes Challenge” as part of the NeurIPS AI conference later this year; this is commonly done with difficult machine learning tasks, as new problems like this one are like catnip for researchers. AI’s changing role in Facebook policyFacebook announced its plans to rely on AI more heavily for moderation in the early days of the COVID-19 crisis. In a press call in March, Mark Zuckerberg said that the company expected more “false positives” — instances of content flagged when it shouldn’t be — with the company’s fleet of 15,000 moderation contractors at home with paid leave. YouTube and Twitter also shifted more of their content moderation to AI around the same time, issuing similar warnings about how an increased reliance on automated moderation might lead to content that doesn’t actually break any platform rules being flagged mistakenly. In spite of its AI efforts, Facebook has been eager to get its human content reviewers back in the office. In mid-April, Zuckerberg gave a timeline for when employees could be expected to get back to the office, noting that content reviewers were high on Facebook’s list of “critical employees” marked for the earliest return. While Facebook warned that its AI systems might remove content too aggressively, hate speech, violent threats and misinformation continue to proliferate on the platform as the coronavirus crisis stretches on. Facebook most recently came under fire for disseminating a viral video discouraging people from wearing face masks or seeking vaccines once they are available — a clear violation of the platform’s rules against health misinformation. The video, an excerpt from a forthcoming pseudo-documentary called “Plandemic,” initially took off on YouTube, but researchers found that Facebook’s thriving ecosystem of conspiracist groups shared it far and wide on the platform, injecting it into mainstream online discourse. The 26-minute-long video, peppered with conspiracies, is also a perfect example of the kind of content an algorithm would have a difficult time making sense of. On Tuesday, Facebook also released a community standards enforcement report detailing its moderation efforts across categories like terrorism, harassment and hate speech. While the results only include a one month span during the pandemic, we can expect to see more of the impact of Facebook’s shift to AI moderation next time around. In a call about the company’s moderation efforts, Zuckerberg noted that the pandemic has made “the human review part” of its moderation much harder, as concerns around protecting user privacy and worker mental health make remote work a challenge for reviewers, but one the company is navigating now. Facebook confirmed to TechCrunch that the company is now allowing a small portion of full-time content reviewers back into the office on a volunteer basis and, according to Facebook Vice President of Integrity Guy Rosen, “the majority” of its contract content reviewers can now work from home. “The humans are going to continue to be a really important part of the equation,” Rosen said.
Social Media via Twitter – TechCrunch https://techcrunch.com May 14, 2020 at 04:25PM
0 Comments
Leave a Reply. |
�
Amazing WeightLoss Categories
All
Archives
November 2020
|


 RSS Feed
RSS Feed
