
|
http://bit.ly/2RubWbV
Dynamic Rendering with Rendertron http://bit.ly/2UsTDpv
Many frontend frameworks rely on JavaScript to show content. This can mean Google might take some time to index your content or update the indexed content.
A workaround we discussed at Google I/O this year is dynamic rendering. There are many ways to implement this. This blog post shows an example implementation of dynamic rendering using Rendertron, which is an open source solution based on headless Chromium.
Which sites should consider dynamic rendering?
Not all search engines or social media bots visiting your website can run JavaScript. Googlebot might take time to run your JavaScript and has some limitations, for example.
Dynamic rendering is useful for content that changes often and needs JavaScript to display.
Your site's user experience (especially the time to first meaningful paint) may benefit from considering hybrid rendering (for example, Angular Universal).
How does dynamic rendering work?
Dynamic rendering means switching between client-side rendered and pre-rendered content for specific user agents.
You will need a renderer to execute the JavaScript and produce static HTML. Rendertron is an open source project that uses headless Chromium to render. Single Page Apps often load data in the background or defer work to render their content. Rendertron has mechanisms to determine when a website has completed rendering. It waits until all network requests have finished and there is no outstanding work.
This post covers:
The sample web app
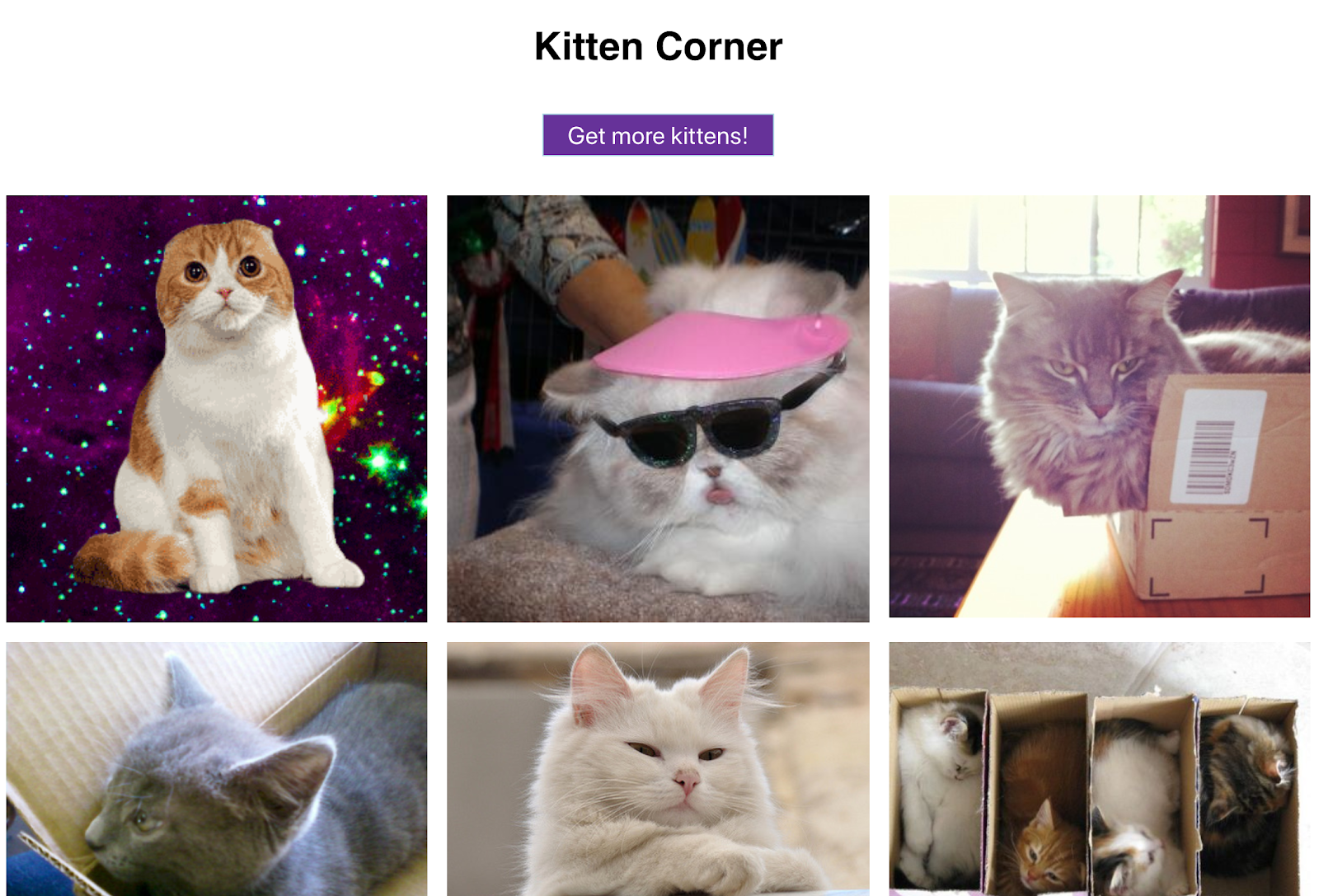
The “kitten corner” web app uses JavaScript to load a variety of cat images from an API and displays them in a grid.
const apiUrl = 'http://bit.ly/2WuKtee';
const tpl = document.querySelector('template').content;
const container = document.querySelector('ul');
function init () {
fetch(apiUrl)
.then(response => response.json())
.then(cats => {
container.innerHTML = '';
cats
.map(cat => {
const li = document.importNode(tpl, true);
li.querySelector('img').src = cat.url;
return li;
}).forEach(li => container.appendChild(li));
})
}
init();
document.querySelector('button').addEventListener('click', init);
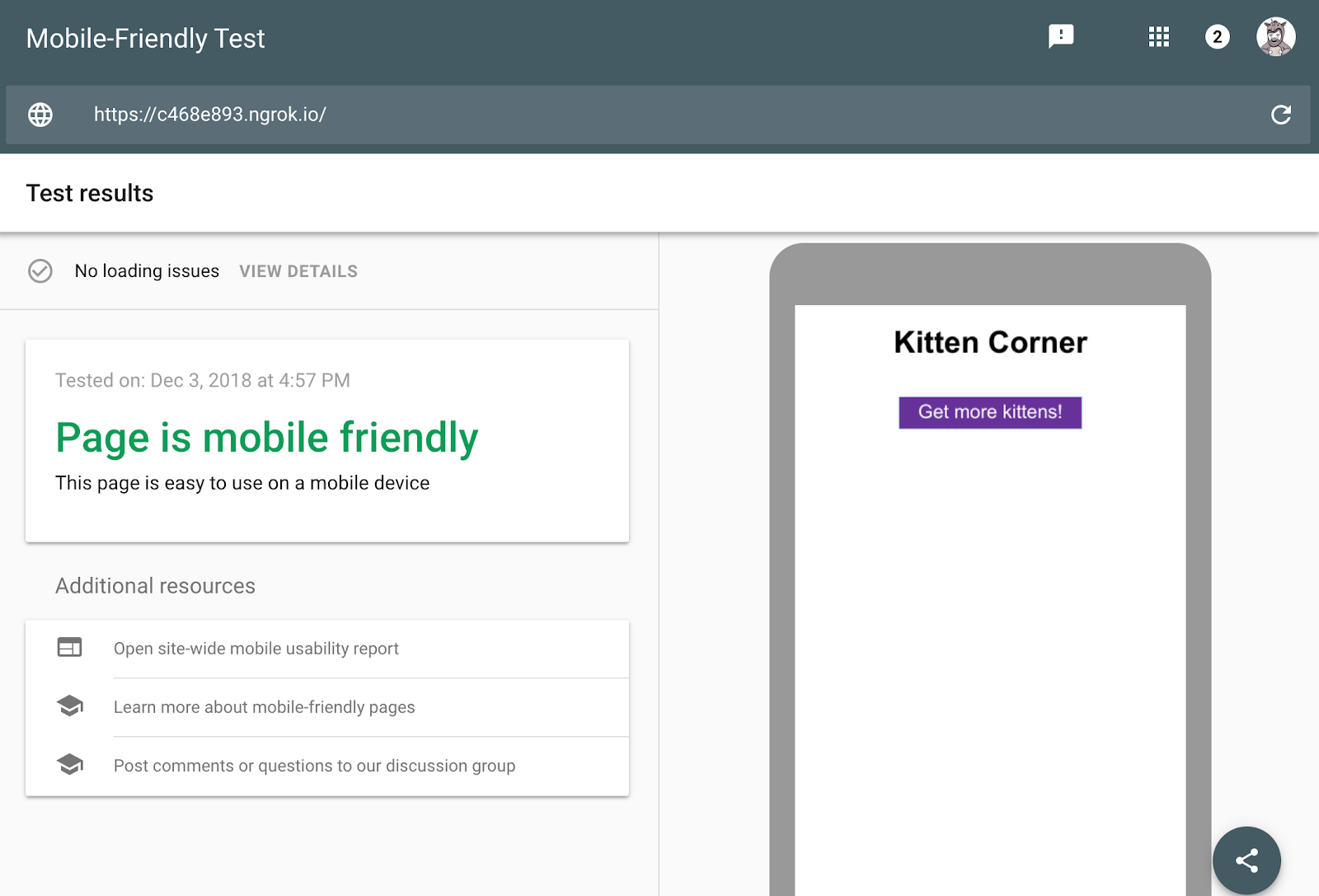
The web app uses modern JavaScript (ES6), which isn't supported in Googlebot yet. We can use the mobile-friendly test to check if Googlebot can see the content:
While this problem is simple to fix, it's a good exercise to learn how to setup dynamic rendering. Dynamic rendering will allow Googlebot to see the cat pictures without changes to the web app code.
Set up the server
To serve the web application, let's use express, a node.js library, to build web servers.
The server code looks like this (find the full project source code here):
const express = require('express');
const app = express();
const DIST_FOLDER = process.cwd() + '/docs';
const PORT = process.env.PORT || 8080;
// Serve static assets (images, css, etc.)
app.get('*.*', express.static(DIST_FOLDER));
// Point all other URLs to index.html for our single page app
app.get('*', (req, res) => {
res.sendFile(DIST_FOLDER + '/index.html');
});
// Start Express Server
app.listen(PORT, () => {
console.log(`Node Express server listening on http://localhost:${PORT} from ${DIST_FOLDER}`);
});
You can try the live example here - you should see a bunch of cat pictures, if you are using a modern browser. To run the project from your computer, you need node.js to run the following commands:
npm install --save express rendertron-middleware node server.js
Then point your browser to http://localhost:8080. Now it’s time to set up dynamic rendering.
Deploy a Rendertron instanceRendertron runs a server that takes a URL and returns static HTML for the URL by using headless Chromium. We'll follow the recommendation from the Rendertron project and use Google Cloud Platform.
Please note that you can get started with the free usage tier, using this setup in production may incur costs according to the Google Cloud Platform pricing.
When you see the Rendertron web interface, you have successfully deployed your own Rendertron instance. Take note of your project’s URL (YOUR_PROJECT_ID.appspot.com) as you will need it in the next part of the process.
Add Rendertron to the server
The web server is using express.js and Rendertron has an express.js middleware. Run the following command in the directory of the server.js file:
npm install --save rendertron-middleware
This command installs the rendertron-middleware from npm so we can add it to the server:
const express = require('express');
const app = express();
const rendertron = require('rendertron-middleware');
Configure the bot list
Rendertron uses the user-agent HTTP header to determine if a request comes from a bot or a user’s browser. It has a well-maintained list of bot user agents to compare with. By default this list does not include Googlebot, because Googlebot can execute JavaScript. To make Rendertron render Googlebot requests as well, add Googlebot to the list of user agents:
const BOTS = rendertron.botUserAgents.concat('googlebot');
const BOT_UA_PATTERN = new RegExp(BOTS.join('|'), 'i');
Rendertron compares the user-agent header against this regular expression later.
Add the middleware
To send bot requests to the Rendertron instance, we need to add the middleware to our express.js server. The middleware checks the requesting user agent and forwards requests from known bots to the Rendertron instance. Add the following code to server.js and don’t forget to substitute “YOUR_PROJECT_ID” with your Google Cloud Platform project ID:
app.use(rendertron.makeMiddleware({
proxyUrl: 'https://YOUR_PROJECT_ID.appspot.com/render',
userAgentPattern: BOT_UA_PATTERN
}));
Bots requesting the sample website receive the static HTML from Rendertron, so the bots don’t need to run JavaScript to display the content.
Testing our setup
To test if the Rendertron setup was successful, run the mobile-friendly test again.
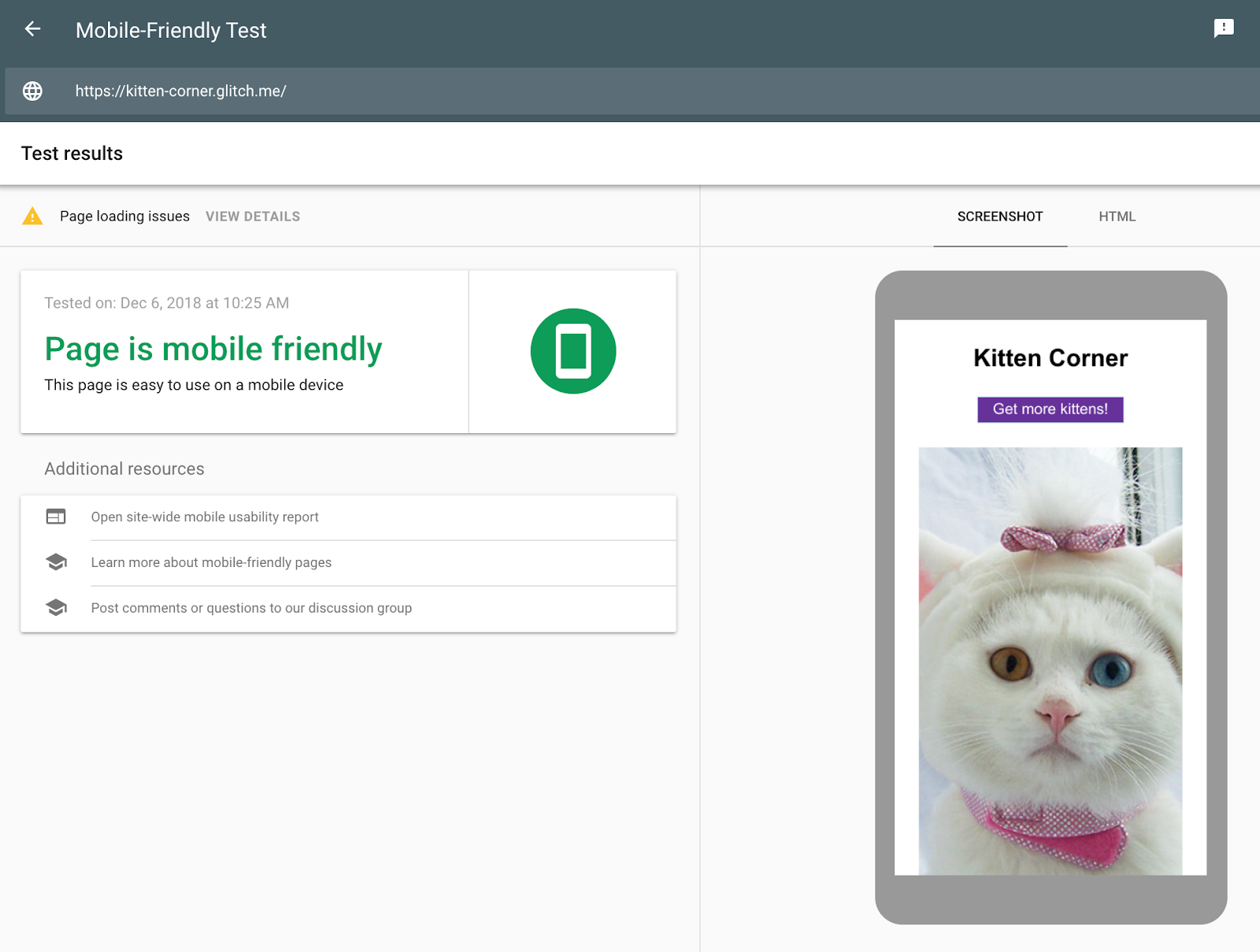
Unlike the first test, the cat pictures are visible. In the HTML tab we can see all HTML the JavaScript code generated and that Rendertron has removed the need for JavaScript to display the content.
Conclusion
You created a dynamic rendering setup without making any changes to the web app. With these changes, you can serve a static HTML version of the web app to crawlers.
Post content Posted by Martin Splitt, Open Web Unicorn

SEO via Google Webmaster Central Blog http://bit.ly/1Ul0du6 January 31, 2019 at 07:45AM
0 Comments
http://bit.ly/2Gf0Q8H
4 Link Building Tips for International SEO by @motokohunt http://bit.ly/2CVJESt  Link building is one of the key activities for a successful SEO strategy. It is perhaps one of the most overlooked SEO activities with regard to the local market SEO work for global websites. There are several reasons why this is happening, and here are some of the common challenges:
Read on to discover are four link building tips that can be easily implemented even by companies with limited resources. 1. Benefit from Websites That Link to Corporate WebsitesBecause most websites usually start out with one or two languages trying to target many countries, those original websites usually have a lot more links coming from external websites than newly launched local websites. When I work on link audits for Japanese and other Asian websites, I always check the links going to the original websites and not just the websites clients requested to be included in the project. For example, if I work on the Japanese website link building for a U.S. company, I check for any Japanese links going to their U.S. website in addition to the Japanese website. By going through those links pointing to the U.S. website, I always find several good links, if not more, from Japanese websites. I usually find even more quality links when the original websites and the target websites use the same languages such as English websites for U.S. and Australia. This is because most websites owners link to the original websites when those launched as they didn’t have a website for the local market. Not many website owners update their links when you launch a website for their local market. It seems that more website owners update the links if they are in a country with uniquely spoken language such as Japanese and Korean. However, not many website owners update the links when your original website uses the same language as their countries such as English and Spanish as they don’t feel the inconveniences as much as Japanese trying to read the content in English. Once you identify the links that should be updated by pointing to the local website instead of the original website, contact the website owner with the information of the URL where you wish them to point the link. In my experience, you might have a higher success rate for getting the links updated when the website owner contacts them directly rather than an email from an SEO professional. Also, check for links pointed to the other languages or local websites within your organization. There is a good chance that you’ll find several links going to the wrong language or country websites. Especially if you have a localized country/language list of sites, it is not uncommon for people to link to the wrong language version. If you find them, contact the site owners to update the URLs in the hyperlinks as I explained above. Updating the links to the best-matched website is not just good for your link building profile, but also good for the website user experience as they can reach the right website for their location. 2. Benefit from Corporate and Other Local Offices’ Marketing ActivitiesThis is another easy way to add links to your local websites. There are many informational websites that are providing their content globally in different languages. However, when that content is localized, the links are often left unchanged. Let’s say your CEO was interviewed or a product was featured by one of the popular industry websites in the U.S. That website is operating in five different languages in 12 countries, and that content which your product was featured would be later published in 12 country websites all of which you happen to have websites, too. If you don’t request, in most cases, they’d leave original the link using your U.S. website URL on all 12 websites. However, just by requesting them to use local website URL in each country version, you will gain 12 relevant links to each of your local website. In order to increase the chance of them updating the links to where you would like them to link, provide them with a list of URLs to be used. Linking to the local market website also helps improve the user experience for their audiences, most websites are willing to update the links. 3. Check Local Competitors’ LinksChecking the links that competitor websites have might seem to be too simple and an obvious tip, but for some reason, many companies overlook this. Digging into an unknown market and different languages can be intimidating and might throw an SEO professional off the normal link building track. The reality is that the link research and analysis tools should do most of the work for you. Using these research tools enable you to do a lot of the analysis even without any local resources. The idea is to check the links your competitors have, compare them against the list of links your local website has, and find the websites that are not linking to your website, but should. Hopefully, you already have a list of top competitors in each country. If not, find out who are constantly ranking well for your non-branded target keywords in the country, and start the research from there. 4. Add Link Building Related Requirements to Marketing, Interviews & Events Best Practice GuidesGaining good quality links is a challenging task, regardless of the size of the website or the company. Let’s make sure that we benefit from every opportunity we have to gain links. Most businesses conduct or participate in some types of marketing activities and events. It is a great way to gain quality links naturally. If the activity is related to a specific product or a line of business, it would be an opportunity to gain links to the specific product page or business category. The challenge is that people who are involved in the marketing activities have little idea about the SEO and the value of links. Perhaps the bigger challenge is for them to remember to include link building while working on their marketing project. You cannot blame them for it as they are not SEO experts. The best way to guarantee to link building is included in the marketing project is to put it in the corporate marketing best practice or the guidelines. This way, the links are handled with each marketing project and are not handled as the afterthought. Below are some of the link building items to be included in the best practice and the guidelines for the marketing projects:
ConclusionWhile a link building project may seem to be a huge task to undertake, especially for local markets, you can still build links effectively even if hiring outside resources is not an option. It takes a bit of preparation and looking at the project globally, not just locally. More Resources: Subscribe to SEJGet our daily newsletter from SEJ's Founder Loren Baker about the latest news in the industry! SEO via Search Engine Journal http://bit.ly/1QNKwvh January 31, 2019 at 07:14AM untitled http://bit.ly/2Wu8a6c SEO via Search Engine Roundtable http://bit.ly/1sYxUD0 January 31, 2019 at 06:49AM
http://bit.ly/2mCbMRl
404 Sitemaps To Remove Them In The New Google Search Console http://bit.ly/2FZU1J8 Google's John Mueller was asked if there is a way in the new Google Search Console to remove old Sitemaps files. He said you can 404 them to remove them. Maybe Google will add a button to delete old Sitemap files there but for now, 404ing them will eventually get them to be removed. SEO via Search Engine Roundtable http://bit.ly/1sYxUD0 January 31, 2019 at 06:37AM Most SEOs Want Fetch As Google Even With URL Inspection Tool http://bit.ly/2DMjqDG Google told us the Fetch as Google tool is going away and being replaced by the URL Inspection Tool. But some SEOs, well, seems like the majority of SEOs, want Google to port over the Fetch as Google tool as well. A Twitter poll with 88 results shows about 75% want both the Fetch as Google and URL Inspection tool. SEO via Search Engine Roundtable http://bit.ly/1sYxUD0 January 31, 2019 at 06:29AM
http://bit.ly/2Bbi83x
Bing: 90% Or More Of Their Core Ranking Algorithm Uses Machine Learning http://bit.ly/2SgiCin Yesterday at SMX West, I did a panel named Man vs Machine covering algorithms versus guidelines and during the Q&A portion, I asked the Bing reps Frédéric Dubut and Nagu Rangan what percentage of the core ranking algorithm is AI or machine learning based. To my surprise, they guessed over 90%. SEO via Search Engine Roundtable http://bit.ly/1sYxUD0 January 31, 2019 at 06:18AM
http://bit.ly/2ToPkeG
New Google Search Console Ports Security Issues Section http://bit.ly/2SfCZwd Google has ported another feature from the old Search Console to the new, the security issues section. Google said on Twitter "We hope you don't need to use a Security Issues tab" but if you do, it has been migrated to the new Search Console. SEO via Search Engine Roundtable http://bit.ly/1sYxUD0 January 31, 2019 at 06:02AM
http://bit.ly/2Gan63M
Google Maps Street View Cars Fleet http://bit.ly/2D0ZNGe 
SEO via Search Engine Roundtable http://bit.ly/1sYxUD0 January 31, 2019 at 05:51AM
http://bit.ly/2UucjFC
How Outbound Links May Affect Rankings by @martinibuster http://bit.ly/2BfSB9f Someone asked me if his linking patterns could cause his site to lose rankings. He said that his informational site is consistently linking to commercial pages. He asked if he should be exclusively linking to informational sites or mix of commercial and informational. Here are the five outbound link factors that I believe can impact rankings. 1. It’s Not the Site. It’s the PageSometimes a site can be about multiple topics. So if the site isn’t an exact match to your niche but had some overlap, then it should be fine. What’s more important is that the site has overlap and that the page is relevant and useful to someone clicking from your site to the other site. Majestic has a tool that displays what they call Topical Trust Flow (TTF). http://bit.ly/1PHest4 TTF is a measure of the topical niches that a domain is in. This is one of the handiest tools I use for understanding what niche a site is in. For most sites you will see that they are members of multiple niche topics. And that’s totally normal. 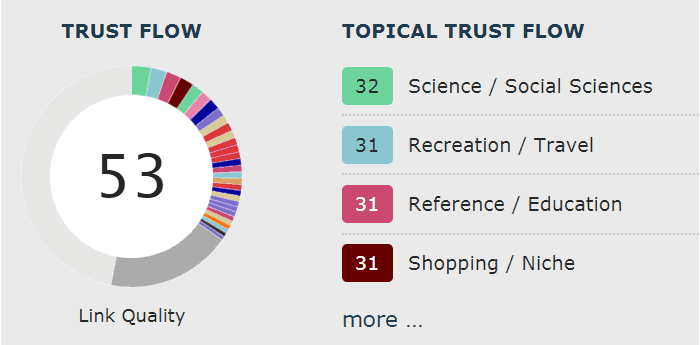 This screenshot of Majestic’s Topical Trust Flow metric shows the different niches that the inbound links reside in. It gives a detailed snapshot of the kind of site you’re dealing with in terms of relevance and spam. This screenshot of Majestic’s Topical Trust Flow metric shows the different niches that the inbound links reside in. It gives a detailed snapshot of the kind of site you’re dealing with in terms of relevance and spam.
So the point I want to make is that if the site is somewhat related but the page is on point related from your page to the linked page, then linking to that page should be fine. 2. Relevance is ImportantWhat you link to should ideally be an exact match for the content being discussed on YOUR Page. An exact match between the context of the paragraph from which the link is on to the linked site, means that it’s good for both. The reason is because what you link to is a signal of what your page is about. 3. Your Links Defines How Legit Your Site IsWho you link to defines what side of the spam/normal wall your site is on. Spammy sites tend to link to other spammy sites as well as to normal sites. Normal sites rarely link to spammy sites. Because of this fact, spammy sites tend to create tight link communities with each other, despite almost consistently linking out to normal sites. Spammy sites have a mix of outbound links to spammy and legit sites. Normal sites less so. 4. The Negative Side of Outbound LinksThe following is an image from a patent showing the linking patterns of spam and normal sites. What YOU need to do is create a site with normal inbound links. Then you need to make sure that the sites/pages you link to also have normal inbound links.  Spammy links and normal links tend to form communities with their linking patterns. While spammy pages may link to normal pages, normal pages rarely link to spammy pages. This creates a map of the Internet that makes it easier to find linking patterns between normal pages, while rejecting the spam links. Spammy links and normal links tend to form communities with their linking patterns. While spammy pages may link to normal pages, normal pages rarely link to spammy pages. This creates a map of the Internet that makes it easier to find linking patterns between normal pages, while rejecting the spam links.
If the sites you link to have spammy outbound links, then maybe you should reconsider linking out to those sites. The point of this is that low quality sites link to normal sites all day long and into the night. Links to normal sites never sleep. But normal sites do not tend to link to low quality sites. If the site you administer is a normal site, then focus on quality of sites that you link to. Content quality is important. But so is understanding who the other site links to and what kinds of sites they are involved with. For example, if the other sites appear to have a lot of inbound links that appear to be paid for, then you might not want to link to them. This is kind of tricky though because any successful site acquires spam links. But there’s a difference between automated links created by spammers and paid links. What Does a Paid Guest Article Look Like? The typical pattern of a paid link within an article is that the article features three links. Is there a spammer handbook somewhere that says there has to be three links, no more no less? Because this is the pattern. The paid link is usually the first and sometimes the second link. If you see a lot of these, then the site is probably engaging in poor linking practices. 5. Does linking to .edu and .gov sites help?Linking out to .edu and .gov pages is ok as long as it’s relevant. If you’re topic is European vacations, in my opinion you’re better off linking to something useful for a traveler, whether that’s something on Instagram or a blog. How likely is ther going to be good travel advice on a .gov site? People believe that linking to .gov and .edu pages will help you rank. This idea has been around since about 2001. If you think Google is so easy to spam that linking to a .edu or .gov site is going to help you, then go ahead. Googlers have consistently debunked the idea that that .gov and .edu pages have a special ranking benefit. There is no patent or research that explicitly or implicitly says that sites with links from .edu and .gov sites are considered better. The entire idea is pure myth. When Google creates a map of the web, pages linking to each other form interlinked communities. It’s like those images of galaxies. Each galaxy can represent a niche topic. Some galaxies are bigger. Some niche topics are smaller and the link communities are smaller. The takeaway is that website linking patterns tend to organize themselves into communities aligned by topic. So if you are wondering if whether linking to a commercial site from an informational site makes a difference, as long as the topics are the same then in my opinion it the link is fine as long as the site/page receiving the link is itself part of a similar link neighborhood. Link neighborhoods overlap, so linking to a related but not an exact match page is perfectly normal. Informational sites routinely link to commercial sites. So it’s not really the consideration of whether it’s a commercial site that should be a worry. What you should worry about is the inbound/outbound link patterns of the site you are linking to. Images by Shutterstock, Modified by Author Subscribe to SEJGet our daily newsletter from SEJ's Founder Loren Baker about the latest news in the industry! SEO via Search Engine Journal http://bit.ly/1QNKwvh January 31, 2019 at 05:00AM
http://bit.ly/2Uqge60
How to Use Python to Analyze SEO Data: A Reference Guide by @hamletbatista http://bit.ly/2SeIjjA Do you find yourself doing the same repetitive SEO tasks each day or facing challenges where there are not tools that can help you? If so, it might be time for you to learn Python. An initial investment of time and sweat will pay off in significantly increased productivity. While I’m writing this article primarily for SEO professionals who are new to programming, I hope that it’ll be useful to those who already have a background in software or Python, but who are looking for an easy-to-scan reference to use in data analysis projects. Table of ContentsPython FundamentalsPython is easy to learn and I recommend you spend an afternoon walking over the official tutorial. I’m going to focus on practical applications for SEO. When writing Python programs, you can decide between Python 2 or Python 3. It is better to write new programs in Python 3, but it is possible your system might come with Python 2 already installed, particularly if you use a Mac. Please also install Python 3 to be able to use this cheat sheet. You can check your Python version using: $python --version Using Virtual EnvironmentsWhen you complete your work, it is important to make sure other people in the community can reproduce your results. They will need to be able to install the same third-party libraries that you use, often using the exact same versions. Python encourages creating virtual environments for this. If your system comes with Python 2, please download and install Python 3 using the Anaconda distribution and run these steps in your command line. $sudo easy_install pip $sudo pip install virtualenv $mkdir seowork $virtualenv -p python3 seowork If you are already using Python 3, please run these alternative steps in your command line: $mkdir seowork $python3 -m venv seowork The next steps allow work in any Python version and allow you to use the virtual environments. $cd seowork $source bin/activate (seowork)$deactivate When you deactivate the environment, you are back to your command line, and the libraries you installed in the environment won’t work. Useful Libraries for Data AnalysisWhenever I start a data analysis project, I like to have at a minimum the following libraries installed: Most of them come included in the Anaconda distribution. Let’s add them to our virtual environment. (seowork)$pip3 install requests (seowork)$pip3 install matplotlib (seowork)$pip3 install requests-html (seowork)$pip3 install pandas You can import them at the beginning of your code like this: import requests from requests_html import HTMLSession import pandas as pd As you require more third-party libraries in your programs, you need an easy way to keep track of them and help others set up your scripts easily. You can export all the libraries (and their version numbers) installed in your virtual environment using: (seowork)$pip3 freeze > requirements.txt When you share this file with your project, anybody else from the community can install all required libraries using this simple command in their own virtual environment: (peer-seowork)$pip3 install -r requirements.txt Using Jupyter NotebooksWhen doing data analysis, I prefer to use Jupyter notebooks as they provide a more convenient environment than the command line. You can inspect the data you are working with and write your programs in an exploratory manner. (seowork)$pip3 install jupyter Then you can run the notebook using: (seowork)$jupyter notebook You will get the URL to open in your browser. Alternatively, you can use Google Colaboratory which is part of GoogleDocs and requires no setup. String FormattingYou will spend a lot of time in your programs preparing strings for input into different functions. Sometimes, you need to combine data from different sources, or convert from one format to another. Say you want to programmatically fetch Google Analytics data. You can build an API URL using Google Analytics Query Explorer, and replace the parameter values to the API with placeholders using brackets. For example:
api_uri = "https://www.googleapis.com/analytics/v3/data/ga?ids={gaid}&"\
"start-date={start}&end-date={end}&metrics={metrics}&"\
"dimensions={dimensions}&segment={segment}&access_token={token}&"\
"max-results={max_results}"
{gaid} is the Google account, i.e., “ga:12345678” {start} is the start date, i.e., “2017-06-01” {end} is the end date, i.e., “2018-06-30” {metrics} is for the list of numeric parameters, i.e., “ga:users”, “ga:newUsers” {dimensions} is the list of categorical parameters, i.e., “ga:landingPagePath”, “ga:date” {segment} is the marketing segments. For SEO we want Organic Search, which is “gaid::-5” {token} is the security access token you get from Google Analytics Query Explorer. It expires after an hour, and you need to run the query again (while authenticated) to get a new one. {max_results} is the maximum number of results to get back up to 10,000 rows. You can define Python variables to hold all these parameters. For example: gaid = “ga:12345678” start = “2017-06-01” end = “2018-06-30” This allows you to fetch data from multiple websites or data ranges fairly easily. Finally, you can combine the parameters with the API URL to produce a valid API request to call. api_uri = api_uri.format( gaid=gaid, start=start, end=end, metrics=metrics, dimensions=dimensions, segment=segment, token=token, max_results=max_results ) Python will replace each place holder with its corresponding value from the variables we are passing. String EncodingEncoding is another common string manipulation technique. Many APIs require strings formatted in a certain way. For example, if one of your parameters is an absolute URL, you need to encode it before you insert it into the API string with placeholders. from urllib import parse url=”https://www.searchenginejournal.com/” parse.quote(url) The output will look like this: ‘https%3A//http://bit.ly/2FYD1CY; which would be safe to pass to an API request. Another example: say you want to generate title tags that include an ampersand (&) or angle brackets (<, >). Those need to be escaped to avoid confusing HTML parsers. import html title= "SEO <News & Tutorials>" html.escape(title) The output will look like this: 'SEO <News & Tutorials>' Similarly, if you read data that is encoded, you can revert it back. html.unescape(escaped_title) The output will read again like the original. Date FormattingIt is very common to analyze time series data, and the date and time stamp values can come in many different formats. Python supports converting from dates to strings and back. For example, after we get results from the Google Analytics API, we might want to parse the dates into datetime objects. This will make it easy to sort them or convert them from one string format to another. from datetime import datetime dt = datetime.strptime(‘Jan 5 2018 6:33PM', '%b %d %Y %I:%M%p') Here %b, %d, etc are directives supported by strptime (used when reading dates) and strftime (used when writing them). You can find the full reference here. Making API RequestsNow that we know how to format strings and build correct API requests, let see how we actually perform such requests. r = requests.get(api_uri) We can check the response to make sure we have valid data. print(r.status_code) print(r.headers[‘content-type’]) You should see a 200 status code. The content type of most APIs is generally JSON. When you are checking redirect chains, you can use the redirect history parameter to see the full chain. print(r.history) In order to get the final URL, use: print(r.url) Data ExtractionA big part of your work is procuring the data you need to perform your analysis. The data will be available from different sources and formats. Let’s explore the most common. Reading from JSONMost APIs will return results in JSON format. We need to parse the data in this format into Python dictionaries. You can use the standard JSON library to do this.
import json
json_response = '{"website_name": "Search Engine Journal", "website_url":"https://www.searchenginejournal.com/"}'
parsed_response = json.loads(json_response)
Now you can easily access any data you need. For example: print(parsed_response[“website_name”]) The output would be: “Search Engine Journal” When you use the requests library to perform API calls, you don’t need to do this. The response object provides a convenient property for this. parsed_response=r.json() Reading from HTML PagesMost of the data we need for SEO is going to be on client websites. While there is no shortage of awesome SEO crawlers, it is important to learn how to crawl yourself to do fancy stuff like automatically grouping pages by page types.
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://www.searchenginejournal.com/')
You can get all absolute links using this: print(r.html.absolute_links) The partial output would look like this:
{'http://jobs.searchenginejournal.com/', 'https://www.searchenginejournal.com/what-i-learned-about-seo-this-year/281301/', …}
Next, let’s fetch some common SEO tags using XPATHs: Page Title
r.html.xpath('//title/text()')
The output is: ['Search Engine Journal - SEO, Search Marketing News and Tutorials'] Meta Description
r.html.xpath("//meta[@name='description']/@content")
Please note that I changed the style of quotes from single to double or I’d get an coding error. The output is: ['Search Engine Journal is dedicated to producing the latest search news, the best guides and how-tos for the SEO and marketer community.'] Canonical
r.html.xpath("//link[@rel='canonical']/@href")
The output is: ['https://www.searchenginejournal.com/'] AMP URL
r.html.xpath("//link[@rel='amphtml']/@href")
Search Engine Journal doesn’t have an AMP URL. Meta Robots
r.html.xpath("//meta[@name='ROBOTS']/@content")
The output is: ['NOODP'] H1s
r.html.xpath("//h1")
The Search Engine Journal home page doesn’t have h1s. HREFLANG Attribute Values
r.html.xpath("//link[@rel='alternate']/@hreflang")
Search Engine Journal doesn’t have hreflang attributes. Google Site Verification
r.html.xpath("//meta[@name='google-site-verification']/@content")
The output is: ['NcZlh5TFoRGYNheLXgxcx9gbVcKCsHDFnrRyEUkQswY', 'd0L0giSu_RtW_hg8i6GRzu68N3d4e7nmPlZNA9sCc5s', 'S-Orml3wOAaAplwsb19igpEZzRibTtnctYrg46pGTzA'] JavaScript Rendering If the page you are analyzing needs JavaScript rendering, you only need to add an extra line of code to support this.
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://www.searchenginejournal.com/')
r.html.render()
The first time you run render() will take a while because Chromium will be downloaded. Rendering Javascript is much slower than without rendering. Reading from XHR requestsAs rendering JavaScript is slow and time consuming, you can use this alternative approach for websites that load JavaScript content using AJAX requests. 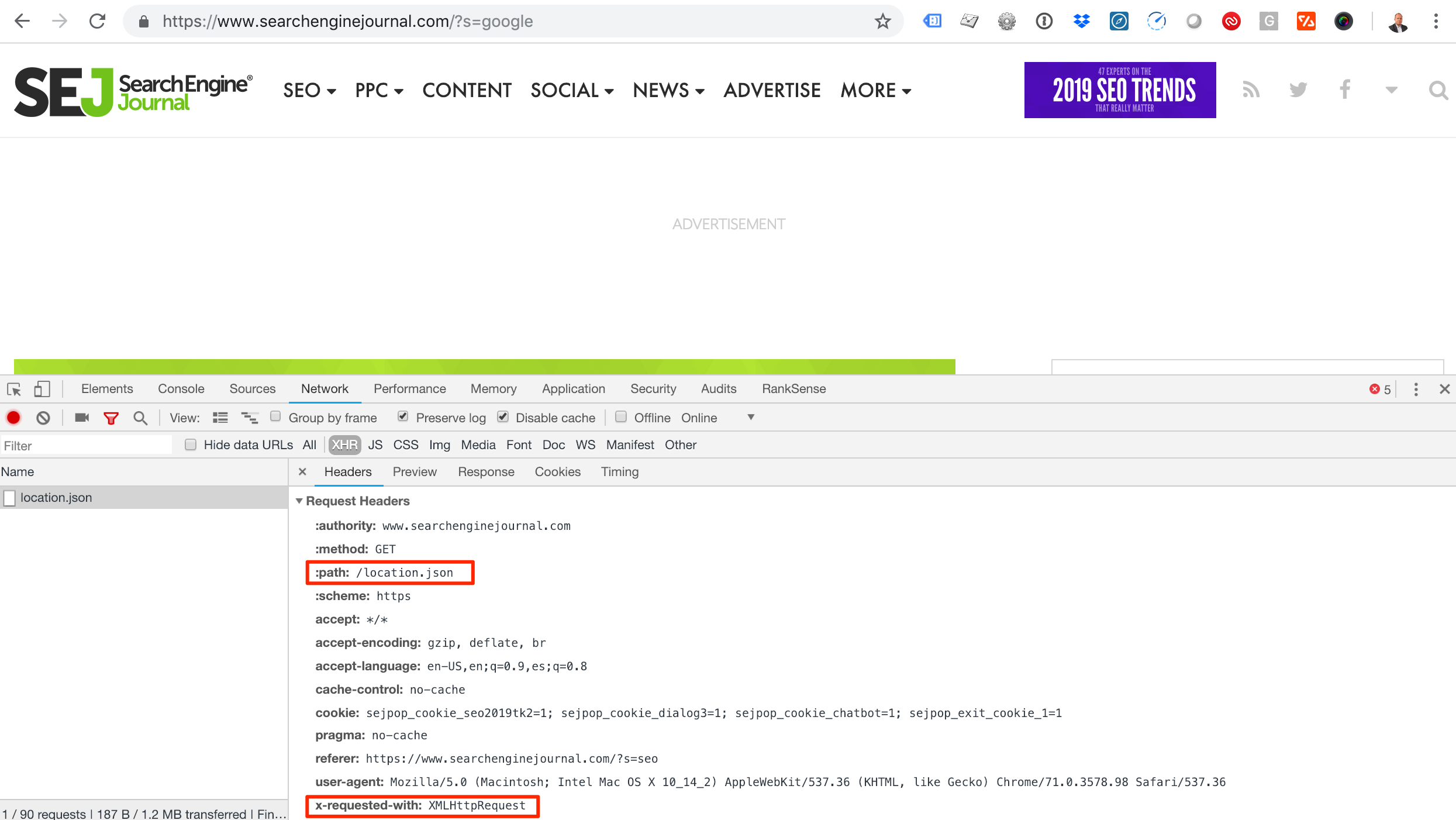 Screenshot showing how to check the request headers of a JSON file using Chrome Developer tools. The path of the JSON file is highlighted, as is the x-requested-with header. Screenshot showing how to check the request headers of a JSON file using Chrome Developer tools. The path of the JSON file is highlighted, as is the x-requested-with header.
ajax_request=’https://www.searchenginejournal.com/location.json’ r = requests.get(ajax_request) results=r.json() You will get the data you need faster as there is no JavaScript rendering or even HTML parsing involved. Reading from Server LogsGoogle Analytics is powerful but doesn’t record or present visits from most search engine crawlers. We can get that information directly from server log files. Let’s see how we can analyze server log files using regular expressions in Python. You can check the regex that I’m using here. import re log_line='66.249.66.1 - - [06/Jan/2019:14:04:19 +0200] "GET / HTTP/1.1" 200 - "" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"' regex='([(\d\.)]+) - - \[(.*?)\] \"(.*?)\" (\d+) - \"(.*?)\" \"(.*?)\"' groups=re.match(regex, line).groups() print(groups) The output breaks up each element of the log entry nicely:
('66.249.66.1', '06/Jan/2019:14:04:19 +0200', 'GET / HTTP/1.1', '200', '', 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)')
You access the user agent string in group six, but lists in Python start at zero, so it is five. print(groups[5]) The output is: 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)' You can learn about regular expression in Python here. Make sure to check the section about greedy vs. non-greedy expressions. I’m using non-greedy when creating the groups. Verifying GooglebotWhen performing log analysis to understand search bot behavior, it is important to exclude any fake requests, as anyone can pretend to be Googlebot by changing the user agent string. Google provides a simple approach to do this here. Let’s see how to automate it with Python. import socket bot_ip = "66.249.66.1" host = socket.gethostbyaddr(bot_ip) print(host[0]) You will get crawl-66-249-66-1.googlebot.com ip = socket.gethostbyname(host[0]) You get ‘66.249.66.1’, which shows that we have a real Googlebot IP as it matches our original IP we extracted from the server log. Reading from URLsAn often-overlooked source of information is the actual webpage URLs. Most websites and content management systems include rich information in URLs. Let’s see how we can extract that. It is possible to break URLs into their components using regular expressions, but it is much simpler and robust to use the standard library urllib for this. from urllib.parse import urlparse url="https://www.searchenginejournal.com/?s=google&search-orderby=relevance&searchfilter=0&search-date-from=January+1%2C+2016&search-date-to=January+7%2C+2019" parsed_url=urlparse(url) print(parsed_url) The output is: ParseResult(scheme='https', netloc='www.searchenginejournal.com', path='/', params='', query='s=google&search-orderby=relevance&searchfilter=0&search-date-from=January+1%2C+2016&search-date-to=January+7%2C+2019', fragment='') For example, you can easily get the domain name and directory path using: print(parsed_url.netloc) print(parsed_url.path) This would output what you would expect. We can further break down the query string to get the url parameters and their values. parsed_query=parse_qs(parsed_url.query) print(parsed_query) You get a Python dictionary as output.
{'s': ['google'],
'search-date-from': ['January 1, 2016'],
'search-date-to': ['January 7, 2019'],
'search-orderby': ['relevance'],
'searchfilter': ['0']}
We can continue and parse the date strings into Python datetime objects, which would allow you to perform date operations like calculating the number of days between the range. I will leave that as an exercise for you. Another common technique to use in your analysis is to break the path portion of the URL by ‘/’ to get the parts. This is simple to do with the split function.
url="https://www.searchenginejournal.com/category/digital-experience/"
parsed_url=urlparse(url)
parsed_url.path.split("/")
The output would be: ['', 'category', 'digital-experience', ''] When you split URL paths this way, you can use this to group a large group of URLs by their top directories. For example, you can find all products and all categories on an ecommerce website when the URL structure allows for this. Performing Basic AnalysisYou will spend most of your time getting the data into the right format for analysis. The analysis part is relatively straightforward, provided you know the right questions to ask. Let’s start by loading a Screaming Frog crawl into a pandas dataframe.
import pandas as pd
df = pd.DataFrame(pd.read_csv('internal_all.csv', header=1, parse_dates=['Last Modified']))
print(df.dtypes)
The output shows all the columns available in the Screaming Frog file, and their Python types. I asked pandas to parse the Last Modified column into a Python datetime object. Let’s perform some example analyses. Grouping by Top Level DirectoryFirst, let’s create a new column with the type of pages by splitting the path of the URLs and extracting the first directory name.
df['Page Type']=df['Address'].apply(lambda x: urlparse(x).path.split("/")[1])
aggregated_df=df[['Page Type','Word Count']].groupby(['Page Type']).agg('sum')
print(aggregated_df)
After we create the Page Type column, we group all pages by type and by total the number of words. The output partially looks like this: seo-guide 736 seo-internal-links-best-practices 2012 seo-keyword-audit 2104 seo-risks 2435 seo-tools 588 seo-trends 3448 seo-trends-2019 2676 seo-value 1528 Grouping by Status Code
status_code_df=df[['Status Code', 'Address']].groupby(['Status Code']).agg('count')
print(status_code_df)
200 218
301 6
302 5
Listing Temporary Redirectstemp_redirects_df=df[df['Status Code'] == 302]['Address'] print(temp_redirects_df) 50 https://www.searchenginejournal.com/wp-content... 116 https://www.searchenginejournal.com/wp-content... 128 https://www.searchenginejournal.com/feed 154 https://www.searchenginejournal.com/wp-content... 206 https://www.searchenginejournal.com/wp-content... Listing Pages with No Contentno_content_df=df[(df['Status Code'] == 200) & (df['Word Count'] == 0 ) ][['Address','Word Count']] 7 https://www.searchenginejournal.com/author/cor... 0 9 https://www.searchenginejournal.com/author/vic... 0 66 https://www.searchenginejournal.com/author/ada... 0 70 https://www.searchenginejournal.com/author/ron... 0 Publishing ActivityLet’s see at what times of the day the most articles are published in SEJ. lastmod = pd.DatetimeIndex(df['Last Modified']) writing_activity_df=df.groupby([lastmod.hour])['Address'].count() 0.0 19 1.0 55 2.0 29 10.0 10 11.0 54 18.0 7 19.0 31 20.0 9 21.0 1 22.0 3 It is interesting to see that there are not many changes during regular working hours. We can plot this directly from pandas. writing_activity_df.plot.bar() 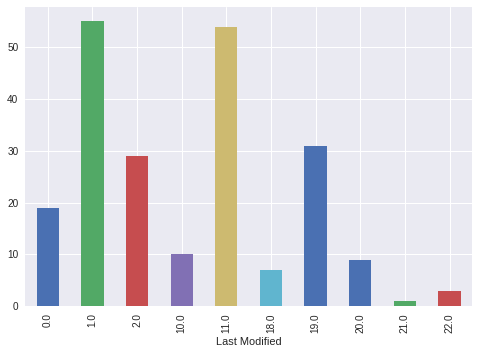 Bar plot showing the times of day that articles are published in Search Engine Journal. The bar plot was generated using Python 3. Bar plot showing the times of day that articles are published in Search Engine Journal. The bar plot was generated using Python 3.
Saving & Exporting ResultsNow we get to the easy part – saving the results of our hard work. Saving to Excelwriter = pd.ExcelWriter(no_content.xlsx') no_content_df.to_excel(writer,’Results’) writer.save() Saving to CSVtemporary_redirects_df.to_csv(‘temporary_redirects.csv’) Additional Resources to Learn MoreWe barely scratched the surface of what is possible when you add Python scripting to your day-to-day SEO work. Here are some links to explore further. More Resources: Image Credits Screenshot taken by author, January 2019 Subscribe to SEJGet our daily newsletter from SEJ's Founder Loren Baker about the latest news in the industry! SEO via Search Engine Journal http://bit.ly/1QNKwvh January 31, 2019 at 04:19AM |
Categories
All
Archives
November 2020
|

 RSS Feed
RSS Feed
