
|
https://ift.tt/3kYKfHb
YouTube is Showing Ads On Non-Monetized Channels via @MattGSouthern https://ift.tt/2KA9RO6 YouTube creators are fuming over a change to the site’s terms of service stating ads will be shown on channels that haven’t opted into monetization It’s not the advertising itself that isn’t sitting well with creators, it’s YouTube’s decision not to pay non-monetized channels for serving ads. Ordinarily, creators would have to join the YouTube Partner Program in order to allow ads to be served on their channel. The main benefit of opting in to serving ads is revenue sharing. Many creators publish on YouTube to earn a side income, while others earn their entire living on the site. Non-monetized channels will not have the opportunity to earn any amount of money when YouTube begins displaying ads on their channel. Advertisement Continue Reading Below These are the changes coming into effect, as per an update to YouTube’s Terms of Service. Right to MonetizeYouTube is adding a new section to its Terms of Service titled Right to Monetize. Agreeing to the new Terms of Service, which is mandatory for all users, means agreeing to everything laid out in the Right to Monetize section. Here’s a snippet of what is stated:
The company says this change is now rolling out slowly to a limited number of videos from channels not in the YouTube Partner Program. Advertisement Continue Reading Below So all creators should be aware that ads may start appearing on some of their videos at any time. As far as I can tell from reading the updated Terms of Service, YouTube will not notify creators when ads begin showing on their content. For creators not currently in the YouTube Partner Program, the new terms makes it very clear no revenue will be earned:
By now you might be asking: If creators want to earn money from ads, why not join the YouTube Partner Program? Here’s why not all channels can simply opt-in to monetization. YouTube Partner Program (YPP)The one and only way for channels to earn ad revenue is by joining the YPP. However, certain conditions need to be met in order to join program. The two conditions that are holding most channels back are:
So it’s the small creators who will be impacted by this change, which only adds to the controversy surrounding YouTube’s new terms. Since announcing this change a few days ago, YouTube has been flooded with videos from creators speaking out against the company’s decision not to share ad revenue. Advertisement Continue Reading Below Their main argument is smaller channels should earn a share of revenue if they’re being forced to serve ads. Established creators are also saying they’re losing confidence in YouTube when it comes to making decisions that benefit the community. Here’s an example of one such video from a favorite creator of mine, Anthony Fantano (mild language warning): For more community reactions, also refer to Team YouTube’s tweet announcing the change. Which, I should add, is currently ratio’d with 2K comments to 1K likes. Advertisement Continue Reading Below In addition to impacting creators, this is almost sure to negatively impact the experience for users as well. There’s a limit to how many ads people are willing to tolerate, and YouTube may now be approaching that limit. On one hand, YouTube could drive more people to sign up for its ad-free Premium service. On the other hand, a greater number of people may reduce their time spent on YouTube or boycott it altogether. Advertisement Continue Reading Below We’ll see over time if YouTube decides to amend its new terms, but for now get prepared for more ads across the platform. Source: YouTube Help Forums SEO via Search Engine Journal https://ift.tt/1QNKwvh November 24, 2020 at 12:14AM
0 Comments
https://ift.tt/33eoltw
How to Tell if You’re Shadowbanned on Social Media https://ift.tt/3pzvpdw 
Suddenly you notice that none of your social media activity seems to be showing up at all. It’s like you don’t even exist on the site… Weird! Is it a bug? Every website suffers from them sometimes, and the interactive features can often be the first to go haywire. Server maintenance could also be the culprit. But another possibility is that you might have been “shadowbanned” (previously called ghostbanned). Accounts that are shadowbanned are put into a kind of invisible mode. In other words, they become a “shadow” that no one can see. In this post, we’ll talk more about what exactly shadowbanning is, and how you can tell if it happened to you. What Is Shadowbanning?Shadowbanning is when your posts or activity don’t show up on a site, but you haven’t received an official ban or notification. It’s a way to let spammers continue to spam without anyone else in the community (or outside of it) seeing what they do. That way, other social media users don’t suffer from spam because they can’t see it. The spammer won’t immediately start to look for ways to get around the ban, because they don’t even realize they’ve been banned. Now, all of this might sound a little odd or shady. Since many websites and apps deny that they shadowban, there’s no way to know for sure that it’s happened. If you suspect a shadowban, a change in the website’s search or newsfeed algorithm might actually be to blame. And since the algorithms are the property of social media companies, it’s not in their best interest to reveal everything about them publicly. Regardless of whether you’ve been penalized deliberately or accidentally, the effect is still the same… no one can see your posts. Sites That ShadowbanThere’s no way of getting a full list of sites that shadowban people, since the practice isn’t entirely out in the open. However, shadowbanning has been reported before under certain circumstances, on sites and apps like Facebook, Instagram, and TikTok, among others. Respondents to a survey called Posting Into the Void reported four general types of shadowbans:
Here’s how to tell if you’ve been shadowbanned on some popular social media sites: Twitter ShadowbanningDoes Twitter actually shadowban people? Well, yes and no. In a blog post, Twitter claimed that they don’t “deliberately make people’s content undiscoverable to everyone except the person who posted it”, and they “certainly don’t shadowban based on political viewpoints or ideology.” However, they did say they “rank tweets and search results” to “address bad-faith actors”. Basically, if Twitter thinks you’re a spammer or a troll, its algorithm will penalize your content. How to Avoid Getting Shadowbanned by TwitterTwitter lists these as some of the factors they use to tell if you’re a “bad-faith actor” or not:
To avoid getting shadowbanned on Twitter, you should confirm your email address and upload a profile picture. Don’t spam people and don’t be overly promotional. If you’re trying to sell a product or service and are posting too much, other users might block your content, causing a shadowban on your account. You should also try to avoid trolling, getting into online arguments, or being too confrontational in your posts and comments. This can lead people to mute or block you. How to Tell If You’re Shadowbanned on TwitterThere’s no way to tell for sure if you’ve been shadowbanned on Twitter. However, you could try using the site Shadowban.eu, which claims to be able to detect a shadowban. 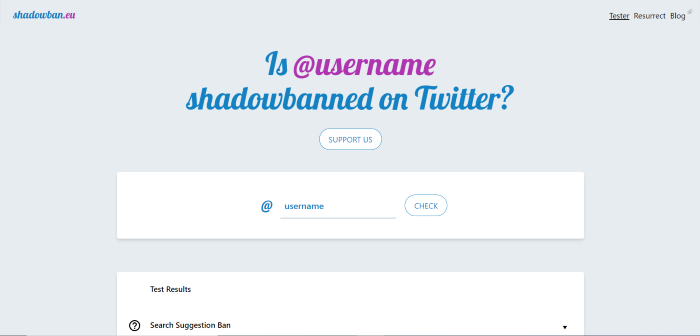
Instagram ShadowbanningHow frustrating is it to work hard at building up an Instagram following, only to see that your posts suddenly aren’t showing up? Like with Twitter, Instagram’s CEO has publicly claimed that “shadowbanning is not a thing”, but as with Twitter, that’s not entirely true. While you personally might not be being shadowbanned, the algorithm could still be hiding your posts. Instagram’s algorithm is designed to remove certain content. Namely, the algorithm penalizes content that Instagram considers “inappropriate”, even if the content doesn’t go against the app’s Community Guidelines. Specifically, they mention sexually-suggestive content. According to their Community Guidelines, spammy content and content associated with illegal activity or violence is also a no-go. Instagram prefers “photos or videos that are appropriate for a diverse audience”… so less family-friendly content may be at risk of a shadowban. How to Tell If You’re Shadowbanned on InstagramThere’s no surefire way to tell if you’ve been shadowbanned on Instagram, but there are sites that say they can test it. Triberr is one option. 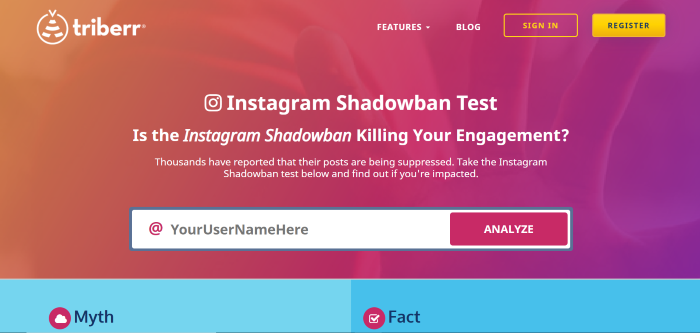
Reddit ShadowbanningShadowbanning on Reddit is a bit different from shadowbanning on other social media sites. Up until 2015, Reddit openly shadowbanned users who broke the site’s rules by hiding their posts. Reddit then announced that the shadowbanning system had been replaced with an account suspension system. Basically, some Reddit staff thought that the shadowban tool had been useful for dealing with bots, but that banning real human users without telling them what they did wrong was unfair. However, the site appears to still occasionally be using shadowbans, with the r/ShadowBan subreddit still active. According to their official content policy, Reddit may enforce their rules by “removal of privileges from, or adding restrictions to, accounts”, and also by “removal of content”, among other methods. How to Avoid Getting Shadowbanned on RedditOf course, to avoid getting shadowbanned on Reddit, you’ll need to follow their rules. But one tricky thing about that is that the rules on Reddit actually depend on the subreddit you are submitting to. You’ll want to read and comment a lot first before submitting your own links. Watch how people react to various types of submissions within a specific subreddit, and then act accordingly. You can also check out this unofficial guide on how to avoid being shadowbanned. Some key points:
How to Tell if You’re Shadowbanned on RedditTo find out if you’re shadowbanned on Reddit, make a post in the r/ShadowBan subreddit. A bot will respond to you, letting you know if you’re shadowbanned. Even if you’re not, the bot will tell you which posts of yours have been removed recently (if any). You could also use a third-party tool, like Am I Shadowbanned? 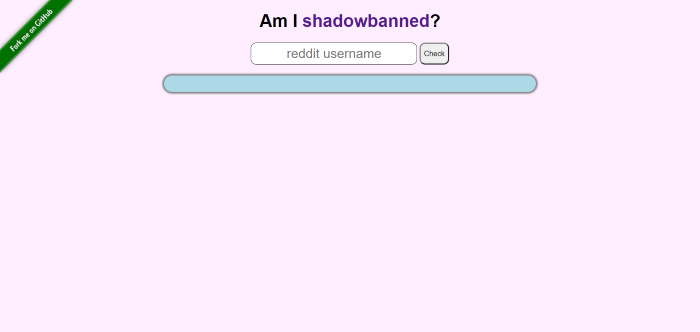
TikTok ShadowbanningTikTok is a popular social network for sharing short videos. Unfortunately, you can get shadowbanned there too (kind of). While there’s no official mention of the term “shadowban” in TikTok’s Community Guidelines, like other social media networks, TikTok uses algorithms to privilege certain content. If you get on the wrong side of the algorithm, fewer people might see the content you post. To have more people see your content and avoid penalties, try to follow best practices for TikTok’s recommendation algorithm, and always follow the Community Guidelines. Stay away from illegal material, violence, hate speech, spam, and other similar topics. To check if you’ve been shadowbanned on TikTok, look at your pageviews and “For You” page statistics. You can also use a hashtag and see if your post shows up under that hashtag. Facebook ShadowbanningFacebook calls its content moderation policy “remove, reduce, and inform.” Basically, content that violates Facebook’s Community Standards will be removed from the site, while other undesirable content (like misleading information) may be less visible on Facebook or have a warning label placed on it. If Facebook is consistently “reducing” your content, that could be considered a type of shadowban. The main thing you can do to trigger a shadowban on Facebook is to share links to fake or misleading information. Content on the site is checked by independent fact-checking organizations. Facebook also penalizes links from websites that its algorithm considers clickbait. Low-authority websites without a lot of inbound and outbound links that generate a lot of clicks on Facebook may be considered clickbait. Facebook groups where a lot of misleading links and clickbait are frequently shared may be shadowbanned. If you’re worried your personal page, business page, or group might have been shadowbanned on Facebook, check for a change in engagement levels on your recent posts. LinkedIn ShadowbanningWhile people don’t often think about getting shadowbanned on LinkedIn, it’s possible for your content’s reach to be throttled there. Like other social media sites, LinkedIn has Community Policies that all members need to follow to avoid problems. Since LinkedIn is a professional site, its content policies are even stricter than other platforms. Not only should your content be safe, legal, and appropriate, it has to be professional as well. Although LinkedIn is obviously a place for career growth and self-promotion, spamming people is still a no-go. You’ll need to respect others’ privacy and intellectual property. You should also avoid harassment or unwanted romantic advances towards other members. If you violate LinkedIn’s policies, they may “limit the visibility of certain content, or remove it entirely.” That said, the LinkedIn algorithm is pretty complicated. Even if your content is perfectly professional and high-quality, it might still not be getting the reach you want. Engagement and relevance are the top two factors to keep in mind when creating content for LinkedIn. YouTube ShadowbanningWhile it’s not exactly a social network, it’s definitely still a site where people go to learn and share content. Can you be shadowbanned from YouTube? Well, YouTube shadowbanning has been in the news because of popular creator PewDiePie. According to his fans, the Swedish videogame YouTuber’s channel was penalized in YouTube search. YouTube’s official response was that it doesn’t shadowban channels, but that some videos might be flagged and need to be reviewed before they show up in search. In an interview with Polygon, they said they were “currently working on fixing the issue.” 7 Ways to Avoid Getting Shadowbanned on Social MediaDifferent social networks have their own opinions on what type of violations merit a shadowban. However, we can definitely see some general trends that are worth noting. Adhere to these guidelines if you want to be safe from a shadowban:
ConclusionYou may not have any idea you are being shadowbanned. At least not at first… though over time, you may begin to suspect it. What you should do to protect yourself is to be careful that what you post isn’t against the terms and conditions of the site or app. Also, try to avoid spamming content, starting fights with and trolling other users, or posting things that might be considered inappropriate. A shadowban can be frustrating, especially if you don’t feel like you deserve one. Maybe you don’t agree with the social media algorithm about what is or isn’t inappropriate, or maybe you think you were having a constructive debate while the algorithm thinks you were being a troll. However, hopefully the tips in this guide can help you avoid being shadowbanned in the future, so your content can get better engagement. What other ways can help people know if they’ve been shadowbanned? Let us know in the comments. The post How to Tell if You’re Shadowbanned on Social Media appeared first on Neil Patel. SEO via Neil Patel https://neilpatel.com November 23, 2020 at 04:28PM
https://ift.tt/3pTMqiX
Snapchat Awarding Users $1 Million a Day to Use Spotlight via @MattGSouthern https://ift.tt/3fsAos7 Snapchat is investing heavily in promoting its new Spotlight feature, to the tune of $1 million per day for users who submit the best content. Spotlight is being described as Snapchat’s answer to TikTok as it allows users to create similar types of content. With Spotlight users can create short videos up to 60 seconds in length and edit them with creative tools such as:
Snapchat is naming the feature “Spotlight” because it is designed to highlight entertaining videos from all users, regardless of the amount of followers or influence they have. Spotlight will also highlight content from users whether or not they have a public profile. Snapchat says in an announcement:
To encourage the use of its new feature, Snapchat is paying users a share of $1 million every day for the best content. Here’s more about Spotlight, how to use it, and how to potentially earn a cut of the prize money. Advertisement Continue Reading Below How Can Users Submit Content to Spotlight?Users can submit content to Spotlight by creating a Snap in the usual fashion. Next, at the top of the ‘Send To’ screen, there’s a new option to select Spotlight. From there, hit the Send button in the bottom right-hand corner and the content will be submitted.
Users have the option to add topics to their Snap before submitting it to Spotlight, which is recommended so it can be surfaced to people interested in that topic. How Does Snapchat Curate Spotlight Content?Snapchat is surfacing submitted content in a new section dedicated to Spotlight videos. Content is surfaced based on users’ individual preferences. Advertisement Continue Reading Below
Snapchat’s algorithm also considers the following factors when curating content:
Before content is surfaced in Spotlight it gets reviewed by moderators to ensure it’s both appropriate and entertaining. Snapchat emphasizes that Spotlight is an entertainment platform and not a place for news or overly political content. How Can Snapchat Users Earn Money From Spotlight Submissions?Whether money is earned from a Spotlight submission is determined using a proprietary formula based on how many unique views it receives compared to other content submitted that day. Advertisement Continue Reading Below Snapchat notes it’s actively monitoring for fraud to ensure view counts are not artificially inflated. Earnings will be paid out to users every day and Snapchat will send a direct message to notify people people who are awarded a share of the money. As far as I can tell there’s no limit to how many times the same person can earn money from Spotlight submissions. So users who win can continue submitting content to potentially earn more prize money. Snapchat is paying out $1 million per day from now until the end of 2020. And maybe even longer, the company says. Spotlight is rolling out slowly and is available first in the following countries:
Advertisement Continue Reading Below For more information see the official Spotlight guidelines here. SEO via Search Engine Journal https://ift.tt/1QNKwvh November 23, 2020 at 04:22PM
https://ift.tt/33eoltw
How to Tell if You’re Shadowbanned on Social Media https://ift.tt/3pzvpdw
Suddenly you notice that none of your social media activity seems to be showing up at all. It’s like you don’t even exist on the site… Weird! Is it a bug? Every website suffers from them sometimes, and the interactive features can often be the first to go haywire. Server maintenance could also be the culprit. But another possibility is that you might have been “shadowbanned” (previously called ghostbanned). Accounts that are shadowbanned are put into a kind of invisible mode. In other words, they become a “shadow” that no one can see. In this post, we’ll talk more about what exactly shadowbanning is, and how you can tell if it happened to you. What Is Shadowbanning?Shadowbanning is when your posts or activity don’t show up on a site, but you haven’t received an official ban or notification. It’s a way to let spammers continue to spam without anyone else in the community (or outside of it) seeing what they do. That way, other social media users don’t suffer from spam because they can’t see it. The spammer won’t immediately start to look for ways to get around the ban, because they don’t even realize they’ve been banned. Now, all of this might sound a little odd or shady. Since many websites and apps deny that they shadowban, there’s no way to know for sure that it’s happened. If you suspect a shadowban, a change in the website’s search or newsfeed algorithm might actually be to blame. And since the algorithms are the property of social media companies, it’s not in their best interest to reveal everything about them publicly. Regardless of whether you’ve been penalized deliberately or accidentally, the effect is still the same… no one can see your posts. Sites That ShadowbanThere’s no way of getting a full list of sites that shadowban people, since the practice isn’t entirely out in the open. However, shadowbanning has been reported before under certain circumstances, on sites and apps like Facebook, Instagram, and TikTok, among others. Respondents to a survey called Posting Into the Void reported four general types of shadowbans:
Here’s how to tell if you’ve been shadowbanned on some popular social media sites: Twitter ShadowbanningDoes Twitter actually shadowban people? Well, yes and no. In a blog post, Twitter claimed that they don’t “deliberately make people’s content undiscoverable to everyone except the person who posted it”, and they “certainly don’t shadowban based on political viewpoints or ideology.” However, they did say they “rank tweets and search results” to “address bad-faith actors”. Basically, if Twitter thinks you’re a spammer or a troll, its algorithm will penalize your content. How to Avoid Getting Shadowbanned by TwitterTwitter lists these as some of the factors they use to tell if you’re a “bad-faith actor” or not:
To avoid getting shadowbanned on Twitter, you should confirm your email address and upload a profile picture. Don’t spam people and don’t be overly promotional. If you’re trying to sell a product or service and are posting too much, other users might block your content, causing a shadowban on your account. You should also try to avoid trolling, getting into online arguments, or being too confrontational in your posts and comments. This can lead people to mute or block you. How to Tell If You’re Shadowbanned on TwitterThere’s no way to tell for sure if you’ve been shadowbanned on Twitter. However, you could try using the site Shadowban.eu, which claims to be able to detect a shadowban.
Instagram ShadowbanningHow frustrating is it to work hard at building up an Instagram following, only to see that your posts suddenly aren’t showing up? Like with Twitter, Instagram’s CEO has publicly claimed that “shadowbanning is not a thing”, but as with Twitter, that’s not entirely true. While you personally might not be being shadowbanned, the algorithm could still be hiding your posts. Instagram’s algorithm is designed to remove certain content. Namely, the algorithm penalizes content that Instagram considers “inappropriate”, even if the content doesn’t go against the app’s Community Guidelines. Specifically, they mention sexually-suggestive content. According to their Community Guidelines, spammy content and content associated with illegal activity or violence is also a no-go. Instagram prefers “photos or videos that are appropriate for a diverse audience”… so less family-friendly content may be at risk of a shadowban. How to Tell If You’re Shadowbanned on InstagramThere’s no surefire way to tell if you’ve been shadowbanned on Instagram, but there are sites that say they can test it. Triberr is one option.
Reddit ShadowbanningShadowbanning on Reddit is a bit different from shadowbanning on other social media sites. Up until 2015, Reddit openly shadowbanned users who broke the site’s rules by hiding their posts. Reddit then announced that the shadowbanning system had been replaced with an account suspension system. Basically, some Reddit staff thought that the shadowban tool had been useful for dealing with bots, but that banning real human users without telling them what they did wrong was unfair. However, the site appears to still occasionally be using shadowbans, with the r/ShadowBan subreddit still active. According to their official content policy, Reddit may enforce their rules by “removal of privileges from, or adding restrictions to, accounts”, and also by “removal of content”, among other methods. How to Avoid Getting Shadowbanned on RedditOf course, to avoid getting shadowbanned on Reddit, you’ll need to follow their rules. But one tricky thing about that is that the rules on Reddit actually depend on the subreddit you are submitting to. You’ll want to read and comment a lot first before submitting your own links. Watch how people react to various types of submissions within a specific subreddit, and then act accordingly. You can also check out this unofficial guide on how to avoid being shadowbanned. Some key points:
How to Tell if You’re Shadowbanned on RedditTo find out if you’re shadowbanned on Reddit, make a post in the r/ShadowBan subreddit. A bot will respond to you, letting you know if you’re shadowbanned. Even if you’re not, the bot will tell you which posts of yours have been removed recently (if any). You could also use a third-party tool, like Am I Shadowbanned?
TikTok ShadowbanningTikTok is a popular social network for sharing short videos. Unfortunately, you can get shadowbanned there too (kind of). While there’s no official mention of the term “shadowban” in TikTok’s Community Guidelines, like other social media networks, TikTok uses algorithms to privilege certain content. If you get on the wrong side of the algorithm, fewer people might see the content you post. To have more people see your content and avoid penalties, try to follow best practices for TikTok’s recommendation algorithm, and always follow the Community Guidelines. Stay away from illegal material, violence, hate speech, spam, and other similar topics. To check if you’ve been shadowbanned on TikTok, look at your pageviews and “For You” page statistics. You can also use a hashtag and see if your post shows up under that hashtag. Facebook ShadowbanningFacebook calls its content moderation policy “remove, reduce, and inform.” Basically, content that violates Facebook’s Community Standards will be removed from the site, while other undesirable content (like misleading information) may be less visible on Facebook or have a warning label placed on it. If Facebook is consistently “reducing” your content, that could be considered a type of shadowban. The main thing you can do to trigger a shadowban on Facebook is to share links to fake or misleading information. Content on the site is checked by independent fact-checking organizations. Facebook also penalizes links from websites that its algorithm considers clickbait. Low-authority websites without a lot of inbound and outbound links that generate a lot of clicks on Facebook may be considered clickbait. Facebook groups where a lot of misleading links and clickbait are frequently shared may be shadowbanned. If you’re worried your personal page, business page, or group might have been shadowbanned on Facebook, check for a change in engagement levels on your recent posts. LinkedIn ShadowbanningWhile people don’t often think about getting shadowbanned on LinkedIn, it’s possible for your content’s reach to be throttled there. Like other social media sites, LinkedIn has Community Policies that all members need to follow to avoid problems. Since LinkedIn is a professional site, its content policies are even stricter than other platforms. Not only should your content be safe, legal, and appropriate, it has to be professional as well. Although LinkedIn is obviously a place for career growth and self-promotion, spamming people is still a no-go. You’ll need to respect others’ privacy and intellectual property. You should also avoid harassment or unwanted romantic advances towards other members. If you violate LinkedIn’s policies, they may “limit the visibility of certain content, or remove it entirely.” That said, the LinkedIn algorithm is pretty complicated. Even if your content is perfectly professional and high-quality, it might still not be getting the reach you want. Engagement and relevance are the top two factors to keep in mind when creating content for LinkedIn. YouTube ShadowbanningWhile it’s not exactly a social network, it’s definitely still a site where people go to learn and share content. Can you be shadowbanned from YouTube? Well, YouTube shadowbanning has been in the news because of popular creator PewDiePie. According to his fans, the Swedish videogame YouTuber’s channel was penalized in YouTube search. YouTube’s official response was that it doesn’t shadowban channels, but that some videos might be flagged and need to be reviewed before they show up in search. In an interview with Polygon, they said they were “currently working on fixing the issue.” 7 Ways to Avoid Getting Shadowbanned on Social MediaDifferent social networks have their own opinions on what type of violations merit a shadowban. However, we can definitely see some general trends that are worth noting. Adhere to these guidelines if you want to be safe from a shadowban:
ConclusionYou may not have any idea you are being shadowbanned. At least not at first… though over time, you may begin to suspect it. What you should do to protect yourself is to be careful that what you post isn’t against the terms and conditions of the site or app. Also, try to avoid spamming content, starting fights with and trolling other users, or posting things that might be considered inappropriate. A shadowban can be frustrating, especially if you don’t feel like you deserve one. Maybe you don’t agree with the social media algorithm about what is or isn’t inappropriate, or maybe you think you were having a constructive debate while the algorithm thinks you were being a troll. However, hopefully the tips in this guide can help you avoid being shadowbanned in the future, so your content can get better engagement. What other ways can help people know if they’ve been shadowbanned? Let us know in the comments. The post How to Tell if You’re Shadowbanned on Social Media appeared first on Neil Patel. SEO via Neil Patel https://neilpatel.com November 23, 2020 at 03:47PM Daily Search Forum Recap: November 23, 2020 https://ift.tt/3kTSeFf Here is a recap of what happened in the search forums today... SEO via Search Engine Roundtable https://ift.tt/1sYxUD0 November 23, 2020 at 03:00PM
https://ift.tt/35VqoEw
5 Free Brand Logo Tools For Your Company https://ift.tt/2V7mkLj 
If you want your business to succeed, you’ll need to pay close attention to your brand strategy. And that strategy starts with a free brand logo. A strong brand creates instant recognition in the marketplace, especially amongst your customers. It also builds loyalty and shows you share your customer’s values. Do this right, and both your customers and your competitors will always remember you. If you’re yet to define and build your brand, this guide can show you where to start. One of the best ways to leave a positive and lasting (visual) imprint of your brand is to create a unique brand logo. Getting your brand logo professionally designed can be expensive. Look at 99Designs research. They found that a professionally-designed logo can cost you anywhere from $400 up to $2500+, with the quality varying depending on the actual cost. That sounds pricey, right? You could take it upon yourself to design your logo from scratch by investing time in learning graphic design. I could even show you where to find some free fonts you could use. Or, I could show you how to design a free brand logo for your company with minimal effort on your part. You see, gone are the days when your only option was to get a graphic designer to create your logo. They usually came with a hefty price tag. Now, you can use online resources to design and create your very own brand logo for free. And you can literally do it within a few minutes. Some of these companies will even allow you to download your logo without having to invest any money. In this article, I’ll walk you through five ways to create a free brand logo for your company in just minutes. 1. Free Logo DesignFree Logo Design is a free brand logo creator that allows you to create a brand logo of your own and incorporate it into your business. You can do this in a few simple steps:
First of all, you’ll need to go to the homepage and enter your company name, as shown. You should notice right off the bat that Free Logo Design gives you several design options as you type. These images are too generic. You’ll want to be more specific. So, pick a category from the drop-down menu and click “Start.” For the “new” Kissmetrics brand logo, I’ll pick “Business & Consulting.” Once you’ve clicked “Get Started,” it will bring you to the design page where a pop-up platform will display auto-generated logo templates from existing images. You’ll see some containing your company’s name. In the “Business & Consulting” category, the software generated 90 designs, with a maximum of 15 per page. For the next step, go through all of the designs and find a logo that you think will:
Once satisfied with your decision, select the desired logo, and click “Add.” From there, it will take you to the logo editor, where you may notice that the text and graphics are overlapping or jumbled up. Each part of the graphic is an individual element, but the text is grouped as one. This is your default logo. You could leave it as it is, but, quite frankly, it won’t look great. In this case, I’d like to move the text under the graphic and center it. Select the text and drag it into position. Once the text is aligned and looks pleasing to the eye, I’ll select all elements and move back to the center of the screen. To do so, click and drag the cursor over the elements you want to move. This creates a selection box of all elements that you can move (or rotate if required). A properties box that shows each element individually will also appear. If you need to edit these elements, you can do so under the “Actions” toolbar. An element’s colors can be edited, moved, flipped, and rotated. You can also edit the color, alignment/curve, and font style of the text if you’re not quite happy with it. Or you can add an extra logo, icon, shape, or more text from the options on the right. Add an extra element or edit logo color if required. Sometimes you can get stuck tweaking your design, potentially for hours. For the “new” Kissmetrics brand logo, the goal is to create a completed logo design in only a few minutes. And that’s all that’s needed. I’m happy with the design. Now, with the design complete, it’s time to download your new brand logo. You can easily do this by clicking “Save” at the top-right corner of the screen. Free Logo Design will then prepare your logo for download. Once ready, it will give you the following options: Click “Download” and enter your name and email address. The finished logo will now be sent to you, free of charge. Although the free PNG file is of a low-resolution, it’s ideal for website use and email signatures. Even the high-resolution download is reasonably priced. Currently, at $39, this includes a PDF, EPS, and vector SVG file. This is a steal compared to the prices I mentioned earlier for a professional design, and it’s very cost-effective for a bootstrapping business startup. Whether you’re a bootstrapping startup or not, realizing your brand’s importance can play a major role in your business’s success. By equipping your company with a new brand logo, you’ll be one step closer to achieving this success. 2. LogomakrAnother free resource with a hands-on approach is Logomakr. With Logomakr, you can instantly make a brand logo for your company. Most of these free online logo makers use similar concepts when designing and editing. They use existing templates on a user-friendly design platform. To create your design with Logomakr: Go to their homepage, and it will greet you with an instructional video. This will quickly run through the simple process of using their platform to design a logo. It also presents you with the following design advice to consider:
With your concept in mind, you’ll need to pick a graphic for your logo. Next, search the million or more graphics in Logomakr’s database by using the search bar at the top left of your screen. For my design, I’ll search “kiss.” 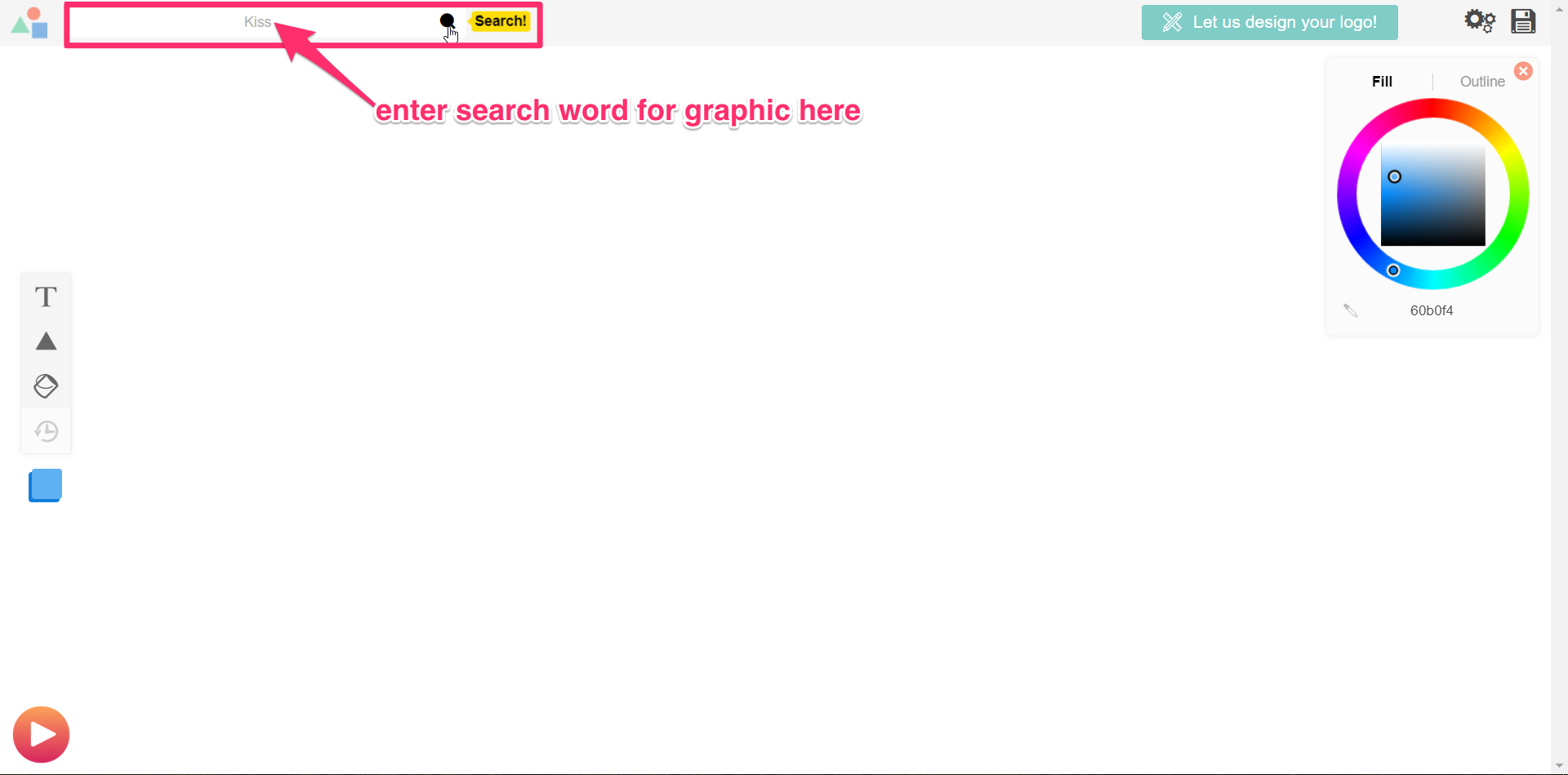
The database should then give hundreds of free-use images to choose from (for that particular search word). Scroll through the results and select the image you’d like to use. You’ll then return to the editing page, where you’ve multiple options to edit your design. You can add text, shapes, paint, scale, move, or change your graphic color. For this example, I’ll scale up the graphic to be larger. That way, it’ll stand out more. Next, you’ll need to add your company name. Using the “add text” function, I’ll add “kissmetrics.” Once you’ve added the text, you’ll notice two drop-down menus at the top of the screen. One is for the font category, and the other is for the font style. Select the font style or category that you think will have the best visual impact on your design. 
You can play around with the text and the scales of the elements (text, image, or shapes) so they sit proportionate to each other. Once you’re satisfied, consider the colors you’ll use in the final design and how that ties in with your branding strategy’s overall color scheme. At Kissmetrics, I’m partial to the color blue. You can change the color in three steps:
Once done, you’re ready to save and download a copy. Do this by clicking on “Save Logo” at the top right corner of your screen. This will then bring you to your final set of options, depending on the logo’s use. To opt for the free version, you’ll need to download and give credit to Logomakr. For this design, I’ll click on “Download And Agree To Give Credit.” Again, to download a higher-res image than the one provided for free, you’ll need to pay a premium. In this case, it’s $19. With the high-res image, you’ll be able to use it on banners, company clothing, and for printing purposes. If you’ve followed the simple steps above, you should now have a free brand logo that you can use as many times as you like. You can do all of that in under 5 minutes, too. 3. CanvaNext on the list of software that offers free downloads is Canva. If you’re not familiar with Canva, it’s simple design software that is quite popular with graphic designers and bloggers to create high-quality images like infographics and featured images. Its popularity is due to its simplistic drag-and-drop design tools and a huge collection of photos, graphics, and fonts. With the easy-to-use platform, you can create your brand logo in five easy steps: Go to Canva’s Online Logo Maker and create an account. Once you’re done, click on the “Start Designing A Custom Logo.” The first thing you’ll want to do is select “Elements” from the toolbar and decide on a category. For this design, I’ll use an image from “Icons.” A library of multiple icons will then appear. Scroll through them until you find an image you can use. Then, select it. Some elements have the word “free” beside them. These are free-use graphics that you can use in your logo design. Now that you have the main graphic for your logo, select the element, and change the color. Remember: always keep your branding theme in mind. So, once again, I’ll use blue. Next, you’ll want to add your company name by selecting the “Text” tool from the toolbar. Similar to “Elements,” you have a library of templates to choose from. Scroll through to find a text that will fit your brand, keeping in mind the “free-use” templates. Find your favorite and click on it. I’ll use “Blue Wood.” 
You’ll notice that the text will center on top of the logo element. Click on it and drag it to where you want it. Move both text and element so that they align with the center of the design template. Once satisfied, it’s time to edit the text. Click on and select the small text above “Blue Wood.” Delete this text. 
Click on and select the text “Blue Wood” and replace it with your company name, “kissmetrics.” Next, edit the text’s color and size by selecting the text and using the text toolbar at the top of your screen. You also have the option to change the font style using the drop-down menu. Your logo should now be ready to download. Click the “Download” button at the top right of the screen. You’ll be given different file types to select for download. The file types available are JPG, PNG, PDF standard, and PDF print. For the Kissmetrics logo, I’ll choose PDF standard. Once downloaded, you’ll be able to view your new brand logo in a PDF reader. Canva doesn’t yet support exporting logos in a vector format. For higher-res graphics, you should make your logo as large as possible and download the PDF print version. Don’t worry; with a PNG file, you’ll be able to add your logo to your website. Another quick, simple, and free way to create a brand logo for your company. 4. GraphicSpringsGraphicSprings is software that allows you to use their platform to design and create a logo for free. To begin your design, go to their logo design page and enter your company name. 
Next, add an image from the database by selecting “Choose Your Graphic” from the side toolbar, left of the screen. A sub-search bar will pop-up under your last selection, with a list of categories underneath. If you know the graphic you’d like to add, enter it into the search bar. GraphicSprings have included an “Internet” category, which is quite fitting, so I’ll use that. Click the category you want, and a database containing stock images or graphics will appear. (Just like the previous software). Can you spot a common theme yet? This simple concept works across each platform, eliminating the need to “reinvent the wheel.” Search through the results, and once you see an image that you’d like to use, select it. After choosing a graphic, the software will create your design and take you to the editing page. Once you’re there, it will prompt you to select the elements for editing. Click on the text to edit it. It will allow you to change the font style, size, and format. You can also add some cool effects like stroke, shadow, or glow. For simplicity, I’ll leave it as it is. The options for editing are also basic. You have the ability to change the color and add some effects. Canva will break the graphic into different elements (similar to Free Logo Design), so you can edit each piece individually. I’ll stick with the color theme of blue, but I’ll keep the two-tone effect. Next, select each element and change the colors accordingly. Once the editing is complete and you’re satisfied with the design, click “Download Your Logo” at the bottom right of the editing page. It will take you to the payment page, where you can buy the high-resolution image for as low as $19.99. To access the vector files with the ability to edit after you purchase it, you’ll need to pay for the standard package, which costs $39.99. With this option, you’ll have the ability to make aftermarket changes to your logo whenever you please. 5. DesignimoDesignimo also requires payment once the design is complete, but you can use the design tools for free to create the graphic for your logo. They previously offered a low-res free download, but they now produce high-res images only. Designimo is similar to Free Logo Design and GraphicSprings in that you enter the name of your company into the search bar and select a category that fits your needs. It’ll then auto-generate multiple graphics using a huge database of existing designs. Again, the level of editing is basic, but the results are solid. It also follows the simple process that Free Logo Design uses:
For a quick video tutorial to help you use the platform, check out how it works here. To ensure your design goes as smoothly as possible, I’ll walk you through the process below. First, go to the homepage, add your company name, and click “Create Logo Now.” Then, select a category from the drop-down menu, ranging from “Alphabetic Text” to “Travel & Hotel.” For this example, I will use the category “Alphabetic Text.” Designimo will provide you with numerous individual designs under each category. While the other categories use existing graphics made up of symbols, the “Alphabetic Text” generates logos in the shape of the letter selected (hence the name). It also files them alphabetically. For the Kissmetrics logo, I’ll select the letter “K,” and go through the results. Each letter has multiple pages of designs, so navigate through them. Once you’ve found the one you’d like to proceed with, select the graphic. You’ll then land on the editing page, equipped with basic design and editing tools. Using the tools available, you can:
For this alphabetical logo, I’ll be a little creative and use the symbol shaped as “K” and use it to start the company name, “Kissmetrics.” By deleting the “k” from the text, I now have a completely different and unique looking logo. Edit the text size or font style, if required. The default font is OK, so I’ll leave it as it is. Next, change the colors to match your theme. If you’re happy with the design, your new brand logo should now be ready to download. Click on “Download Now” or “Save For Future” (if you’d like to come back and work on it). First, you’ll need to register your details and sign up for an account to download your image. You’ll then be brought to an order confirmation page, to confirm and proceed to checkout. Pay and download. The cost for a high-res image, including PNG, JPG, and EPS Vector files, is $29.95. Although not free, the brand logo you can create and download using this software is a high-quality graphic at a relatively low price. ConclusionWhen it comes to starting a new business, the tasks on your to-do list, along with the costs of setting everything up, can be overwhelming. But creating a brand logo for your company doesn’t have to be. Branding should be the core of your company’s marketing strategy. Your brand should tell a story, and part of that story is your logo. Being an expert in graphic design or outsourcing to a professional was once the norm (and it still is for many brands). But now, the Internet is full of innovative people with new ideas and free software that can help new businesses reduce their startup costs. With user-friendly tools, it’s possible to create a free brand logo for your company in minutes. These platforms also help prevent you from being paralyzed by options. Previously, you may have been up all night studying “how-to-design” videos on YouTube. Now you don’t have to. These platforms do most of the designing for you and, and they’ll even give you some quick tutorials. All you have to bring to the table is a good idea and an eye for a visually-pleasing design. With your brand’s color and theme in mind, pick the software that is easiest for you and get started designing a free brand logo today. In terms of user-friendliness, design results, or cost, which free brand logo software would you recommend? The post 5 Free Brand Logo Tools For Your Company appeared first on Neil Patel. SEO via Neil Patel https://neilpatel.com November 23, 2020 at 02:57PM
https://ift.tt/35VqoEw
5 Free Brand Logo Tools For Your Company https://ift.tt/2V7mkLj
If you want your business to succeed, you’ll need to pay close attention to your brand strategy. And that strategy starts with a free brand logo. A strong brand creates instant recognition in the marketplace, especially amongst your customers. It also builds loyalty and shows you share your customer’s values. Do this right, and both your customers and your competitors will always remember you. If you’re yet to define and build your brand, this guide can show you where to start. One of the best ways to leave a positive and lasting (visual) imprint of your brand is to create a unique brand logo. Getting your brand logo professionally designed can be expensive. Look at 99Designs research. They found that a professionally-designed logo can cost you anywhere from $400 up to $2500+, with the quality varying depending on the actual cost. That sounds pricey, right? You could take it upon yourself to design your logo from scratch by investing time in learning graphic design. I could even show you where to find some free fonts you could use. Or, I could show you how to design a free brand logo for your company with minimal effort on your part. You see, gone are the days when your only option was to get a graphic designer to create your logo. They usually came with a hefty price tag. Now, you can use online resources to design and create your very own brand logo for free. And you can literally do it within a few minutes. Some of these companies will even allow you to download your logo without having to invest any money. In this article, I’ll walk you through five ways to create a free brand logo for your company in just minutes. 1. Free Logo DesignFree Logo Design is a free brand logo creator that allows you to create a brand logo of your own and incorporate it into your business. You can do this in a few simple steps:
First of all, you’ll need to go to the homepage and enter your company name, as shown. You should notice right off the bat that Free Logo Design gives you several design options as you type. These images are too generic. You’ll want to be more specific. So, pick a category from the drop-down menu and click “Start.” For the “new” Kissmetrics brand logo, I’ll pick “Business & Consulting.” Once you’ve clicked “Get Started,” it will bring you to the design page where a pop-up platform will display auto-generated logo templates from existing images. You’ll see some containing your company’s name. In the “Business & Consulting” category, the software generated 90 designs, with a maximum of 15 per page. For the next step, go through all of the designs and find a logo that you think will:
Once satisfied with your decision, select the desired logo, and click “Add.” From there, it will take you to the logo editor, where you may notice that the text and graphics are overlapping or jumbled up. Each part of the graphic is an individual element, but the text is grouped as one. This is your default logo. You could leave it as it is, but, quite frankly, it won’t look great. In this case, I’d like to move the text under the graphic and center it. Select the text and drag it into position. Once the text is aligned and looks pleasing to the eye, I’ll select all elements and move back to the center of the screen. To do so, click and drag the cursor over the elements you want to move. This creates a selection box of all elements that you can move (or rotate if required). A properties box that shows each element individually will also appear. If you need to edit these elements, you can do so under the “Actions” toolbar. An element’s colors can be edited, moved, flipped, and rotated. You can also edit the color, alignment/curve, and font style of the text if you’re not quite happy with it. Or you can add an extra logo, icon, shape, or more text from the options on the right. Add an extra element or edit logo color if required. Sometimes you can get stuck tweaking your design, potentially for hours. For the “new” Kissmetrics brand logo, the goal is to create a completed logo design in only a few minutes. And that’s all that’s needed. I’m happy with the design. Now, with the design complete, it’s time to download your new brand logo. You can easily do this by clicking “Save” at the top-right corner of the screen. Free Logo Design will then prepare your logo for download. Once ready, it will give you the following options: Click “Download” and enter your name and email address. The finished logo will now be sent to you, free of charge. Although the free PNG file is of a low-resolution, it’s ideal for website use and email signatures. Even the high-resolution download is reasonably priced. Currently, at $39, this includes a PDF, EPS, and vector SVG file. This is a steal compared to the prices I mentioned earlier for a professional design, and it’s very cost-effective for a bootstrapping business startup. Whether you’re a bootstrapping startup or not, realizing your brand’s importance can play a major role in your business’s success. By equipping your company with a new brand logo, you’ll be one step closer to achieving this success. 2. LogomakrAnother free resource with a hands-on approach is Logomakr. With Logomakr, you can instantly make a brand logo for your company. Most of these free online logo makers use similar concepts when designing and editing. They use existing templates on a user-friendly design platform. To create your design with Logomakr: Go to their homepage, and it will greet you with an instructional video. This will quickly run through the simple process of using their platform to design a logo. It also presents you with the following design advice to consider:
With your concept in mind, you’ll need to pick a graphic for your logo. Next, search the million or more graphics in Logomakr’s database by using the search bar at the top left of your screen. For my design, I’ll search “kiss.”
The database should then give hundreds of free-use images to choose from (for that particular search word). Scroll through the results and select the image you’d like to use. You’ll then return to the editing page, where you’ve multiple options to edit your design. You can add text, shapes, paint, scale, move, or change your graphic color. For this example, I’ll scale up the graphic to be larger. That way, it’ll stand out more. Next, you’ll need to add your company name. Using the “add text” function, I’ll add “kissmetrics.” Once you’ve added the text, you’ll notice two drop-down menus at the top of the screen. One is for the font category, and the other is for the font style. Select the font style or category that you think will have the best visual impact on your design.
You can play around with the text and the scales of the elements (text, image, or shapes) so they sit proportionate to each other. Once you’re satisfied, consider the colors you’ll use in the final design and how that ties in with your branding strategy’s overall color scheme. At Kissmetrics, I’m partial to the color blue. You can change the color in three steps:
Once done, you’re ready to save and download a copy. Do this by clicking on “Save Logo” at the top right corner of your screen. This will then bring you to your final set of options, depending on the logo’s use. To opt for the free version, you’ll need to download and give credit to Logomakr. For this design, I’ll click on “Download And Agree To Give Credit.” Again, to download a higher-res image than the one provided for free, you’ll need to pay a premium. In this case, it’s $19. With the high-res image, you’ll be able to use it on banners, company clothing, and for printing purposes. If you’ve followed the simple steps above, you should now have a free brand logo that you can use as many times as you like. You can do all of that in under 5 minutes, too. 3. CanvaNext on the list of software that offers free downloads is Canva. If you’re not familiar with Canva, it’s simple design software that is quite popular with graphic designers and bloggers to create high-quality images like infographics and featured images. Its popularity is due to its simplistic drag-and-drop design tools and a huge collection of photos, graphics, and fonts. With the easy-to-use platform, you can create your brand logo in five easy steps: Go to Canva’s Online Logo Maker and create an account. Once you’re done, click on the “Start Designing A Custom Logo.” The first thing you’ll want to do is select “Elements” from the toolbar and decide on a category. For this design, I’ll use an image from “Icons.” A library of multiple icons will then appear. Scroll through them until you find an image you can use. Then, select it. Some elements have the word “free” beside them. These are free-use graphics that you can use in your logo design. Now that you have the main graphic for your logo, select the element, and change the color. Remember: always keep your branding theme in mind. So, once again, I’ll use blue. Next, you’ll want to add your company name by selecting the “Text” tool from the toolbar. Similar to “Elements,” you have a library of templates to choose from. Scroll through to find a text that will fit your brand, keeping in mind the “free-use” templates. Find your favorite and click on it. I’ll use “Blue Wood.”
You’ll notice that the text will center on top of the logo element. Click on it and drag it to where you want it. Move both text and element so that they align with the center of the design template. Once satisfied, it’s time to edit the text. Click on and select the small text above “Blue Wood.” Delete this text.
Click on and select the text “Blue Wood” and replace it with your company name, “kissmetrics.” Next, edit the text’s color and size by selecting the text and using the text toolbar at the top of your screen. You also have the option to change the font style using the drop-down menu. Your logo should now be ready to download. Click the “Download” button at the top right of the screen. You’ll be given different file types to select for download. The file types available are JPG, PNG, PDF standard, and PDF print. For the Kissmetrics logo, I’ll choose PDF standard. Once downloaded, you’ll be able to view your new brand logo in a PDF reader. Canva doesn’t yet support exporting logos in a vector format. For higher-res graphics, you should make your logo as large as possible and download the PDF print version. Don’t worry; with a PNG file, you’ll be able to add your logo to your website. Another quick, simple, and free way to create a brand logo for your company. 4. GraphicSpringsGraphicSprings is software that allows you to use their platform to design and create a logo for free. To begin your design, go to their logo design page and enter your company name.
Next, add an image from the database by selecting “Choose Your Graphic” from the side toolbar, left of the screen. A sub-search bar will pop-up under your last selection, with a list of categories underneath. If you know the graphic you’d like to add, enter it into the search bar. GraphicSprings have included an “Internet” category, which is quite fitting, so I’ll use that. Click the category you want, and a database containing stock images or graphics will appear. (Just like the previous software). Can you spot a common theme yet? This simple concept works across each platform, eliminating the need to “reinvent the wheel.” Search through the results, and once you see an image that you’d like to use, select it. After choosing a graphic, the software will create your design and take you to the editing page. Once you’re there, it will prompt you to select the elements for editing. Click on the text to edit it. It will allow you to change the font style, size, and format. You can also add some cool effects like stroke, shadow, or glow. For simplicity, I’ll leave it as it is. The options for editing are also basic. You have the ability to change the color and add some effects. Canva will break the graphic into different elements (similar to Free Logo Design), so you can edit each piece individually. I’ll stick with the color theme of blue, but I’ll keep the two-tone effect. Next, select each element and change the colors accordingly. Once the editing is complete and you’re satisfied with the design, click “Download Your Logo” at the bottom right of the editing page. It will take you to the payment page, where you can buy the high-resolution image for as low as $19.99. To access the vector files with the ability to edit after you purchase it, you’ll need to pay for the standard package, which costs $39.99. With this option, you’ll have the ability to make aftermarket changes to your logo whenever you please. 5. DesignimoDesignimo also requires payment once the design is complete, but you can use the design tools for free to create the graphic for your logo. They previously offered a low-res free download, but they now produce high-res images only. Designimo is similar to Free Logo Design and GraphicSprings in that you enter the name of your company into the search bar and select a category that fits your needs. It’ll then auto-generate multiple graphics using a huge database of existing designs. Again, the level of editing is basic, but the results are solid. It also follows the simple process that Free Logo Design uses:
For a quick video tutorial to help you use the platform, check out how it works here. To ensure your design goes as smoothly as possible, I’ll walk you through the process below. First, go to the homepage, add your company name, and click “Create Logo Now.” Then, select a category from the drop-down menu, ranging from “Alphabetic Text” to “Travel & Hotel.” For this example, I will use the category “Alphabetic Text.” Designimo will provide you with numerous individual designs under each category. While the other categories use existing graphics made up of symbols, the “Alphabetic Text” generates logos in the shape of the letter selected (hence the name). It also files them alphabetically. For the Kissmetrics logo, I’ll select the letter “K,” and go through the results. Each letter has multiple pages of designs, so navigate through them. Once you’ve found the one you’d like to proceed with, select the graphic. You’ll then land on the editing page, equipped with basic design and editing tools. Using the tools available, you can:
For this alphabetical logo, I’ll be a little creative and use the symbol shaped as “K” and use it to start the company name, “Kissmetrics.” By deleting the “k” from the text, I now have a completely different and unique looking logo. Edit the text size or font style, if required. The default font is OK, so I’ll leave it as it is. Next, change the colors to match your theme. If you’re happy with the design, your new brand logo should now be ready to download. Click on “Download Now” or “Save For Future” (if you’d like to come back and work on it). First, you’ll need to register your details and sign up for an account to download your image. You’ll then be brought to an order confirmation page, to confirm and proceed to checkout. Pay and download. The cost for a high-res image, including PNG, JPG, and EPS Vector files, is $29.95. Although not free, the brand logo you can create and download using this software is a high-quality graphic at a relatively low price. ConclusionWhen it comes to starting a new business, the tasks on your to-do list, along with the costs of setting everything up, can be overwhelming. But creating a brand logo for your company doesn’t have to be. Branding should be the core of your company’s marketing strategy. Your brand should tell a story, and part of that story is your logo. Being an expert in graphic design or outsourcing to a professional was once the norm. But now, the Internet is full of innovative people with new ideas and free software that can help new businesses reduce their startup costs. With user-friendly tools, it’s possible to create a free brand logo for your company in minutes. These platforms also help prevent you from being paralyzed by options. Previously, you may have been up all night studying “how-to-design” videos on YouTube. Now you don’t have to. These platforms do most of the designing for you and, and they’ll even give you some quick tutorials. All you have to bring to the table is a good idea and an eye for a visually-pleasing design. With your brand’s color and theme in mind, pick the software that is easiest for you and get started designing a free brand logo today. In terms of user-friendliness, design results, or cost, which free brand logo software would you recommend? The post 5 Free Brand Logo Tools For Your Company appeared first on Neil Patel. SEO via Neil Patel https://neilpatel.com November 23, 2020 at 02:51PM
https://ift.tt/2UT4r2x
How to Get Reviews on Amazon https://ift.tt/35XRNpu 
Amazon reviews are a crucial part of customers’ decision-making process. Without the ability to touch, feel, and test a product in real life, consumers look to reviews to determine whether or not an item will fit their needs. In fact, a survey by Dimensional Research found that reviews impact the buying decisions of 90% of consumers. If you want to boost your e-commerce sales and you’re wondering how to get reviews on Amazon, then you need to make a strategic plan. Below, we’ll cover some of the ways you can get more reviews and build a successful Amazon e-commerce business. Why Getting Amazon Reviews Are Important for Your BusinessFeedvisor found that 89% of consumers are more likely to buy products from Amazon than any other retail site. On Amazon, reviews are especially important. Their commitment to customer satisfaction has meant a lot of resources invested in making sure the sales stick. Individual businesses using the platform for e-commerce need to collect positive reviews for products to rank high and be found by consumers. Most people won’t buy a product if it has a low review rating. A study by Podium found consumers won’t engage with businesses that have less than a 3.3-star rating. Likewise, Podium found consumers aren’t only concerned with price; they also want a good buying experience, and most are willing to pay up to 15% more to ensure that happens. Concerns about shipping times, product functionality, and quality are all present in your consumers’ minds as they shop. Reviews help consumers understand how products function, how reliable they are, and how the business selling the product interacts with their consumers. They also offer data insights into consumer behavior, wants, and needs. Even negative reviews can have a positive impact on your business if you know how to use them. 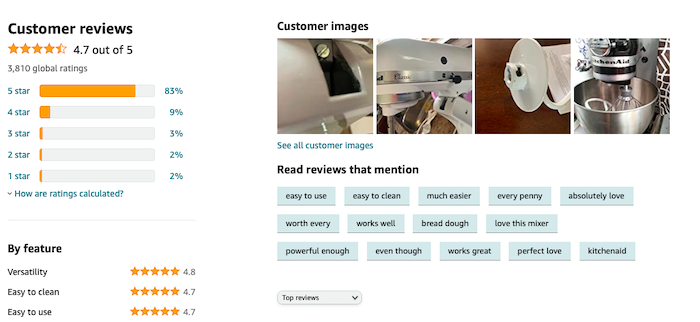
If a business understands how to get reviews on Amazon, they have a better chance of driving conversions, keeping long term customers, and being successful in an e-commerce platform. If you want to increase your sales on Amazon, reviews are an excellent place to start. Here are just a few ways Amazon reviews can impact your e-commerce business. Amazon Reviews Build Trust Between Brands and ConsumersAmazon reviews are one of the best ways to attract customers to your products. They help customers understand your product and how it works, so they can feel confident in their purchases. In an online world, where regular sensory information is excluded, this is a huge selling point for new customers. Consumers have a natural skepticism when shopping online. Negative reviews can give the impression that your product is a scam or your business is unreliable. Reviews also act as natural, word-of-mouth marketing between consumers. Amazon Reviews Affect SEOAmazon considers the consumer experience to be the most important factor in its service offerings. From ordering to delivery, return, and review options, they aim to make their customers happy. Amazon encourages its retailers to emulate this value in their stores. They reward retailers with high customer rankings by promoting their products more often in search results. This is because the higher your reviews are, the more likely you will do right by your customers. Likewise, many consumers will modify their search results to put top-rated items first. If your product is well-liked and well-reviewed, it is likely to be seen by more people. Amazon Reviews Offer InsightsAmazon reviews can help you understand what your customers like or don’t like about your products. It also allows you to compare your products to your competitors and understand what your consumer base is looking for. Even negative reviews can offer valuable insights into how your products are resonating with consumers. Paying attention to these details can improve your review ratings and your product catalog as a whole. Amazon Reviews Drive ConversionsConsumers don’t trust ads and other content from brands. As a result, many are more skeptical than ever about buying products online. From a consumer standpoint, the more you know about an online product, the more comfortable you are going ahead with a purchase. Amazon reviews act as informative, crowd-sourced opinions about products that consumers can trust. The more people believe your brand is honest and trustworthy, the more likely they are to interact with it. Amazon Reviews are a Free Marketing ToolPeople trust other people when making purchasing decisions. Think about the days before online shopping. If you were looking for a new TV, you’d probably ask some family members, maybe a couple of friends, or even a neighbor about the best deals in town. Online reviews work in a similar fashion. They allow consumers to communicate with each other about which products are good, bad, and which arrived as advertised. A study by BrightLocal found 84% of consumers trust online reviews just as much as they trust personal recommendations. Amazon reviews can act as a grapevine marketing tactic that builds brand loyalty, encourages repeat business, and helps get your product into consumers’ minds. 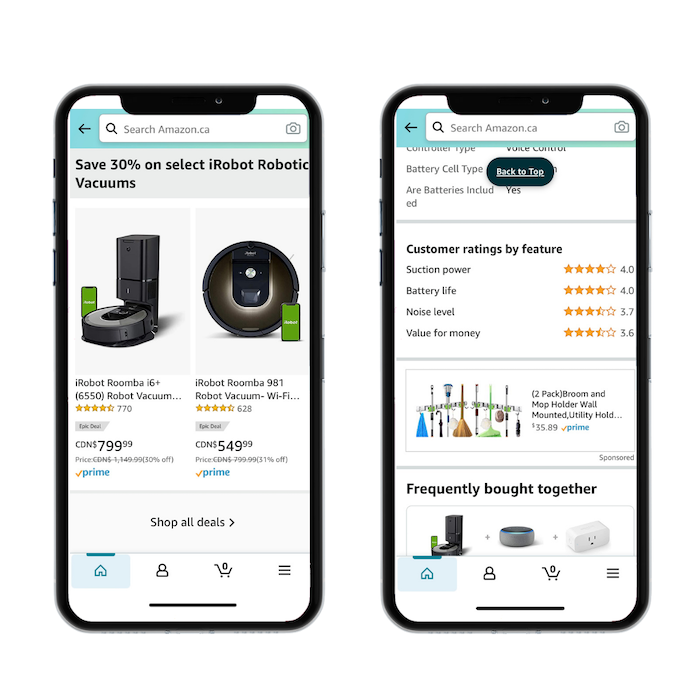
How to Get Reviews on Amazon: 6 TipsAmazon has strict rules to ensure reviews are honest, legitimate, and unsolicited, so there’s no quick fix to getting your reviews up and running. To start with, Amazon does not allow businesses to solicit positive or false reviews from their customers through discounts or gift cards. That means if you want to know how to get reviews on Amazon, you may need to get creative. Here are a few simple ways to get the Amazon reviews you need to grow your Amazon e-commerce business — and make sure your customers are happy. Request a Amazon Buyer ReviewIf you want to learn how to get reviews on Amazon, your first step is to ask. Amazon automatically requests feedback on all purchased products. Their simple email template is uninspiring and won’t always convince a customer to leave a review. Instead, send a personalized review request to customers. This will let them know you care about their experience and are engaged with your consumer community. Make leaving a review easy by adding a link in your email that takes them directly to the review page. You can also use automated e-commerce tools to send these requests like SageMailer, Jungle Scout, and Feedback Express. Asking for reviews can also increase the number of positive reviews — because unhappy customers tend to leave reviews more often than happy customers. Use a Packaging Inset to Request a ReviewAdding a small slip to encourage customers to review your products is an easy way to get more Amazon reviews. Packaging inserts are also a good way to minimize returns by ensuring customers know how to easily contact your business. Because of Amazon’s strict non-soliciting guidelines, there are a few rules you should follow when using a product insert. Do not:
Join Amazon Vine to Get More Amazon ReviewsAmazon Vine is an internal service Amazon launched to validate the reviewing process and stop sellers from purchasing fake reviews. Customers can sign up to be verified reviewers and receive free products in return. For sellers, you can join as long as you commit to giving away products for free. Amazon Vine is a great way to get genuine, honest reviews from verified reviewers. Each reviewer is hand-picked by Amazon to ensure quality and commitment. Amazon Vine reviews are thorough and usually include images or videos to help other customers understand the products. 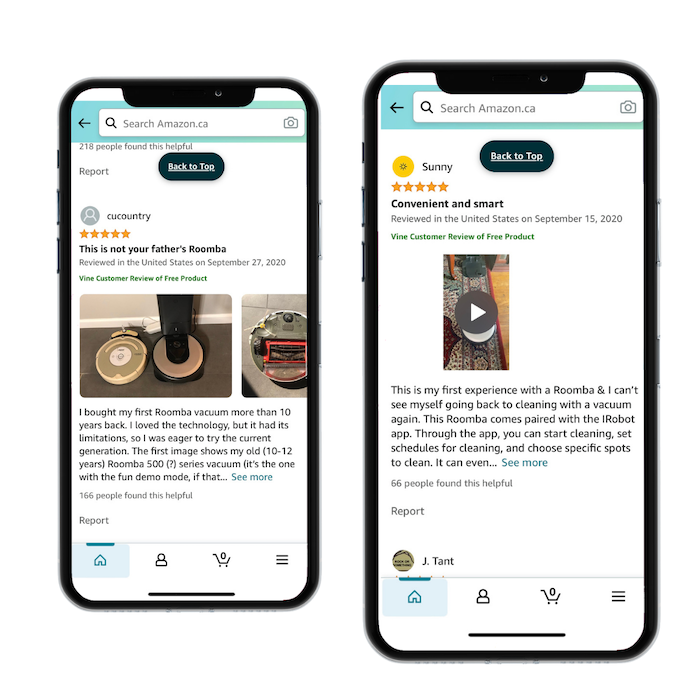
Vine reviews are a great way to collect reviews and tap into the SEO benefits that Amazon reviews offer. The downside of this program is there is no guarantee your reviews will be positive. If you’re just learning how to get reviews on Amazon, negative reviews might seem like a big deal. The upside is negative reviews can give you insights on how to improve your products and services. So don’t get too down about negative feedback. Be Honest in Your Amazon ListingOne of the easiest ways to get bad reviews is to mislead your customers in your listing. It’s never a good idea to promise features that won’t be delivered or to lie about sizing, quality, or durability. If you’ve ever been on the internet, you know how much people love to leave bad reviews. In fact, you’re probably more likely to get a review when a customer dislikes a product than when they do like it. Be diligent and concise when describing your products in your listings. Don’t try to oversell or manipulate your consumers. Chances are, it will come back to bite you. Reach Out to Customers Who Reviewed Related Products on AmazonYou can find customers who have bought related products to yours by looking for the “Customers Who Bought This Item Also Bought” and “Customers Who Viewed This Item Also Viewed” sliders. 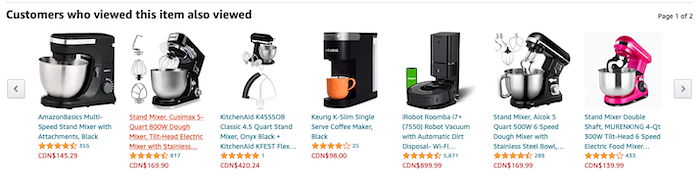
It’s a good idea to check out competitor products and reach out to competitor reviewers. Not only is this a good way to win business, but you have a better chance of getting a review from someone who is already interested in related products, such as k-cups if they just purchased a new Keurig coffee machine. You can usually find reviewer information by clicking on their name and viewing their profile. Then, send an email or social message to see if they are interested in reviewing your product. Even if they say no, you’ve got your product into their mind, and that’s a great marketing opportunity. Provide a Great Customer ExperienceNegative reviews don’t just happen when a customer doesn’t like the product — they can come from customers who are unhappy with the customer service. If you want to avoid negative reviews, make sure the product you offer is what the customer expects. Don’t make promises you can’t keep, and don’t mislead your consumers. Look at reviews regularly and respond to customer questions and messages. If several customers mention your sizing chart is off, it may be time to readjust it. If a customer receives a damaged product, make it right. Amazon takes pride in its customer service tactics and they reward retailers who follow their lead. If you want to rank high and make sales on Amazon, you need to put customers first. Looking for more tips for gaining reviews? Here’s an extra 10 tips to convince your customers to review your products. ConclusionRemember, good customer experience is one of Amazon’s core values. Make sure your product is up to par before going out and searching for reviews. Then, use the strategies above to encourage users to share their two cents. And remember, bad reviews can be a drag, but look at them as an opportunity to improve your products or services. A few bad reviews are unlikely to tank your business. If you want to boost your Amazon marketing plan even more, choose the right Amazon marketing agency. Have you found any other tricks for getting more reviews on Amazon? Share them below. The post How to Get Reviews on Amazon appeared first on Neil Patel. SEO via Neil Patel https://neilpatel.com November 23, 2020 at 02:40PM
https://ift.tt/3jT4SUz
Social Shorts: YouTube expands ad inventory, Twitter launches Fleets, more https://ift.tt/3nQQQVT 
YouTube to show ads on channels that aren’t in the Partner ProgramIn it’s latest terms of service update, YouTube creators agree to allow the service to monetize their content with ads (or by charging users for access) but are not necessarily entitled to revenue sharing. To be eligible for YouTube’s revenue sharing Partner Program (YPP), channels need to have more than 4,000 watch hours in the past 12 months and have more than 1,000 subscribers among other requirements. “This is part of our ongoing investments in new solutions, like Home Feed ads, that help advertisers responsibly tap into the full scale of YouTube to connect with their audiences and grow their businesses,” said YouTube. Why we care. For advertisers, the change means there’s more advertising inventory on YouTube, which as the company noted, it has been focusing on. That begs the brand safety question. Do you want your ads on these channels? YouTube says its brand suitability controls have gotten better since many advertisers boycotted the platform over ads running alongside objectionable content in 2017. “Over the past three years, we improved our ability to identify appropriate placements for advertisers, in part by working closely with our advertising partners and industry organizations,” the company said. For creators, of course, it means YouTube can start earning revenue from your content before you become eligible for YPP. YouTube gets into audio adsAlso from YouTube: Audio ads. Audio ads are now in beta on YouTube along with new “dynamic music lineups” of channels across music genres such as Latin, K-pop as well as lineups aimed at moods and interests like fitness. “Music lineups and audio ads make it possible to be there, at scale, whether YouTube is being watched front and center or playing as the backdrop to daily life,” YouTube wrote in a blog post this week. YouTube’s 15-second audio ads are accompanied by an image or simple animation and include a link to the advertiser’s site. They are largely aimed at driving brand awareness and are available to advertisers now in Google Ads and Display & Video 360 on a CPM basis. Why we care. YouTube’s scale makes its entry into digital audio advertising particularly notable. There are more than 2 billion monthly music listeners on YouTube, according to the company. Spotify, by contrast, reaches 185 million monthly users with its ad supported product. Internet audio advertising revenue reached $2.7 billion last year, up 21% from the previous year, the IAB reported. YouTube says more than 50% of logged-in users who listen to music content in a day consume more than 10 minutes of music content on the platform. Update for Instagram Branded Content ads: New workflow, product tags and moreInstagram advertisers can now create Branded Content ads without creators having to post organically first. Branded content ads on Instagram have been around since June 2019. With the new workflow, advertisers request ad creation access from creators. After a creator approves the request, they’ll then be notified to approve or decline branded ads that appear from the advertiser under the creator’s handle. In Stories, Branded Content ads can now include tappable elements — mentions, hashtags, location. In addition, Instagram will begin testing Product Tags in Branded Content ads. Currently, creators’ branded content posts that have product tags can’t be promoted by brands as ads. Why we care. The new workflow streamlines the process for both brands and creators. Product Tags are potentially a big opportunity as Instagram becomes a bigger driving force in commerce. “More and more, people are shopping directly from the creators they love on Instagram – this new ad format is another way brands can provide a seamless shopping experience on Instagram,” the company said. Twitter launches Fleets, tests social audio featureTwitter has launched Fleets, the company’s version of Stories allows users to post content that vanishes after 24 hours. “You can Fleet text, reactions to Tweets, photos or videos and customize your Fleets with various background and text options,” Twitter explained. Twitter is also testing an audio feature with which users can come together for live conversations, similar to the Clubhouse app that’s still in pilot. In an effort to avoid the moderation challenges that Clubhouse has found, Twitter said, ““We are going to launch this first experiment of spaces to a very small group of people — a group of people who are disproportionately impacted by abuse and harm on the platform: women and those from marginalized backgrounds,” TechCrunch reported. Why we care. Twitter has been slower to develop new product features commonplace on other platforms — even LinkedIn had Stories first — but Fleets and audio features could bring interesting new ways of engaging users on the platform beyond 280 characters. Twitter also continues to work on voice tweets for Android and is testing audio DMs. Facebook injects more machine learning in content moderationFacebook is now using machine learning to power how it prioritizes content slated for human review. Currently, flagged posts are largely reviewed in the order in which they were flagged. “In the future, an amalgam of various machine learning algorithms will be used to sort this queue, prioritizing posts based on three criteria: their virality, their severity, and the likelihood they’re breaking the rules,” The Verge reported. Why we care. Conspiracy theories, misinformation and extremist content have been able to spread rapidly on Facebook. Leaning on more machine learning to take these three criteria into account cloud help the company respond to harmful content faster. That, in turn, might help improve brand safety on the platform. About The AuthorGinny Marvin is Third Door Media’s Editor-in-Chief, running the day to day editorial operations across all publications and overseeing paid media coverage. Ginny Marvin writes about paid digital advertising and analytics news and trends for Search Engine Land, Marketing Land and MarTech Today. With more than 15 years of marketing experience, Ginny has held both in-house and agency management positions. She can be found on Twitter as @ginnymarvin. SEO via Search Engine Land https://ift.tt/1BDlNnc November 23, 2020 at 01:29PM
https://ift.tt/2UT4r2x
How to Get Reviews on Amazon https://ift.tt/35XRNpu
Amazon reviews are a crucial part of customers’ decision-making process. Without the ability to touch, feel, and test a product in real life, consumers look to reviews to determine whether or not an item will fit their needs. In fact, a survey by Dimensional Research found that reviews impact the buying decisions of 90% of consumers. If you want to boost your e-commerce sales and you’re wondering how to get reviews on Amazon, then you need to make a strategic plan. Below, we’ll cover some of the ways you can get more reviews and build a successful Amazon e-commerce business. Why Getting Amazon Reviews Are Important for Your BusinessFeedvisor found that 89% of consumers are more likely to buy products from Amazon than any other retail site. On Amazon, reviews are especially important. Their commitment to customer satisfaction has meant a lot of resources invested in making sure the sales stick. Individual businesses using the platform for e-commerce need to collect positive reviews for products to rank high and be found by consumers. Most people won’t buy a product if it has a low review rating. A study by Podium found consumers won’t engage with businesses that have less than a 3.3-star rating. Likewise, Podium found consumers aren’t only concerned with price; they also want a good buying experience, and most are willing to pay up to 15% more to ensure that happens. Concerns about shipping times, product functionality, and quality are all present in your consumers’ minds as they shop. Reviews help consumers understand how products function, how reliable they are, and how the business selling the product interacts with their consumers. They also offer data insights into consumer behavior, wants, and needs. Even negative reviews can have a positive impact on your business if you know how to use them.
If a business understands how to get reviews on Amazon, they have a better chance of driving conversions, keeping long term customers, and being successful in an e-commerce platform. If you want to increase your sales on Amazon, reviews are an excellent place to start. Here are just a few ways Amazon reviews can impact your e-commerce business. Amazon Reviews Build Trust Between Brands and ConsumersAmazon reviews are one of the best ways to attract customers to your products. They help customers understand your product and how it works, so they can feel confident in their purchases. In an online world, where regular sensory information is excluded, this is a huge selling point for new customers. Consumers have a natural skepticism when shopping online. Negative reviews can give the impression that your product is a scam or your business is unreliable. Reviews also act as natural, word-of-mouth marketing between consumers. Amazon Reviews Affect SEOAmazon considers the consumer experience to be the most important factor in its service offerings. From ordering to delivery, return, and review options, they aim to make their customers happy. Amazon encourages its retailers to emulate this value in their stores. They reward retailers with high customer rankings by promoting their products more often in search results. This is because the higher your reviews are, the more likely you will do right by your customers. Likewise, many consumers will modify their search results to put top-rated items first. If your product is well-liked and well-reviewed, it is likely to be seen by more people. Amazon Reviews Offer InsightsAmazon reviews can help you understand what your customers like or don’t like about your products. It also allows you to compare your products to your competitors and understand what your consumer base is looking for. Even negative reviews can offer valuable insights into how your products are resonating with consumers. Paying attention to these details can improve your review ratings and your product catalog as a whole. Amazon Reviews Drive ConversionsConsumers don’t trust ads and other content from brands. As a result, many are more skeptical than ever about buying products online. From a consumer standpoint, the more you know about an online product, the more comfortable you are going ahead with a purchase. Amazon reviews act as informative, crowd-sourced opinions about products that consumers can trust. The more people believe your brand is honest and trustworthy, the more likely they are to interact with it. Amazon Reviews are a Free Marketing ToolPeople trust other people when making purchasing decisions. Think about the days before online shopping. If you were looking for a new TV, you’d probably ask some family members, maybe a couple of friends, or even a neighbor about the best deals in town. Online reviews work in a similar fashion. They allow consumers to communicate with each other about which products are good, bad, and which arrived as advertised. A study by BrightLocal found 84% of consumers trust online reviews just as much as they trust personal recommendations. Amazon reviews can act as a grapevine marketing tactic that builds brand loyalty, encourages repeat business, and helps get your product into consumers’ minds.
How to Get Reviews on Amazon: 6 TipsAmazon has strict rules to ensure reviews are honest, legitimate, and unsolicited, so there’s no quick fix to getting your reviews up and running. To start with, Amazon does not allow businesses to solicit positive or false reviews from their customers through discounts or gift cards. That means if you want to know how to get reviews on Amazon, you may need to get creative. Here are a few simple ways to get the Amazon reviews you need to grow your Amazon e-commerce business — and make sure your customers are happy. Request a Amazon Buyer ReviewIf you want to learn how to get reviews on Amazon, your first step is to ask. Amazon automatically requests feedback on all purchased products. Their simple email template is uninspiring and won’t always convince a customer to leave a review. Instead, send a personalized review request to customers. This will let them know you care about their experience and are engaged with your consumer community. Make leaving a review easy by adding a link in your email that takes them directly to the review page. You can also use automated e-commerce tools to send these requests like SageMailer, Jungle Scout, and Feedback Express. Asking for reviews can also increase the number of positive reviews — because unhappy customers tend to leave reviews more often than happy customers. Use a Packaging Inset to Request a ReviewAdding a small slip to encourage customers to review your products is an easy way to get more Amazon reviews. Packaging inserts are also a good way to minimize returns by ensuring customers know how to easily contact your business. Because of Amazon’s strict non-soliciting guidelines, there are a few rules you should follow when using a product insert. Do not:
Join Amazon Vine to Get More Amazon ReviewsAmazon Vine is an internal service Amazon launched to validate the reviewing process and stop sellers from purchasing fake reviews. Customers can sign up to be verified reviewers and receive free products in return. For sellers, you can join as long as you commit to giving away products for free. Amazon Vine is a great way to get genuine, honest reviews from verified reviewers. Each reviewer is hand-picked by Amazon to ensure quality and commitment. Amazon Vine reviews are thorough and usually include images or videos to help other customers understand the products.
Vine reviews are a great way to collect reviews and tap into the SEO benefits that Amazon reviews offer. The downside of this program is there is no guarantee your reviews will be positive. If you’re just learning how to get reviews on Amazon, negative reviews might seem like a big deal. The upside is negative reviews can give you insights on how to improve your products and services. So don’t get too down about negative feedback. Be Honest in Your Amazon ListingOne of the easiest ways to get bad reviews is to mislead your customers in your listing. It’s never a good idea to promise features that won’t be delivered or to lie about sizing, quality, or durability. If you’ve ever been on the internet, you know how much people love to leave bad reviews. In fact, you’re probably more likely to get a review when a customer dislikes a product than when they do like it. Be diligent and concise when describing your products in your listings. Don’t try to oversell or manipulate your consumers. Chances are, it will come back to bite you. Reach Out to Customers Who Reviewed Related Products on AmazonYou can find customers who have bought related products to yours by looking for the “Customers Who Bought This Item Also Bought” and “Customers Who Viewed This Item Also Viewed” sliders.
It’s a good idea to check out competitor products and reach out to competitor reviewers. Not only is this a good way to win business, but you have a better chance of getting a review from someone who is already interested in related products, such as k-cups if they just purchased a new Keurig coffee machine. You can usually find reviewer information by clicking on their name and viewing their profile. Then, send an email or social message to see if they are interested in reviewing your product. Even if they say no, you’ve got your product into their mind, and that’s a great marketing opportunity. Provide a Great Customer ExperienceNegative reviews don’t just happen when a customer doesn’t like the product — they can come from customers who are unhappy with the customer service. If you want to avoid negative reviews, make sure the product you offer is what the customer expects. Don’t make promises you can’t keep, and don’t mislead your consumers. Look at reviews regularly and respond to customer questions and messages. If several customers mention your sizing chart is off, it may be time to readjust it. If a customer receives a damaged product, make it right. Amazon takes pride in its customer service tactics and they reward retailers who follow their lead. If you want to rank high and make sales on Amazon, you need to put customers first. Looking for more tips for gaining reviews? Here’s an extra 10 tips to convince your customers to review your products. ConclusionRemember, good customer experience is one of Amazon’s core values. Make sure your product is up to par before going out and searching for reviews. Then, use the strategies above to encourage users to share their two cents. And remember, bad reviews can be a drag, but look at them as an opportunity to improve your products or services. A few bad reviews are unlikely to tank your business. If you want to boost your Amazon marketing plan even more, choose the right Amazon marketing agency. Have you found any other tricks for getting more reviews on Amazon? Share them below. The post How to Get Reviews on Amazon appeared first on Neil Patel. SEO via Neil Patel https://neilpatel.com November 23, 2020 at 01:03PM |
Categories
All
Archives
November 2020
|
 RSS Feed
RSS Feed
