
|
https://selnd.com/2Mcxah5
SMX Advanced is next week. Don’t miss out! https://selnd.com/2McwBnt 
Hey there, marketing friend… did you know that SMX Advanced is happening NEXT WEEK? I’m so flippin’ excited! I’ve been to a lot of different conferences during my 11 years in the industry, but seriously… nothing compares to SMX Advanced. This show is like summer camp for search marketers – a once-a-year pilgrimage to the Pacific Northwest where SEO and SEM experts learn something new, train with the best, see old friends, and make lasting connections. I’d love to see you there! Check out the agenda, featuring 40+ keynotes and sessions (including brand new Advanced Q&A clinics – my personal favorite), 30+ exhibitors, and seven engaging networking opportunities… like the *drumroll* 2019 Search Engine Land Awards & Afterparty. (Entry is included with your SMX pass. Woot!) If you book your pass before June 3, you’ll save up to $300 off on-site rates. (It’s also a good idea to book now in case we sell out of tickets in the coming days.) Ready to register? Secure your pass now! Have any questions? Shoot them directly to me at ldonovan@thirddoormedia.com. I’m happy to help in any way I can. See you in Seattle :-) Psst… Really – if you see me at the show, say hi! About The AuthorLauren Donovan has worked in online marketing since 2006, specializing in content generation, organic social media, community management, real-time journalism, and holistic social befriending. She currently serves as the Content Marketing Manager at Third Door Media, parent company to Search Engine Land, Marketing Land, MarTech Today, SMX, and The MarTech Conference. SEO via Search Engine Land https://selnd.com/1BDlNnc May 29, 2019 at 03:42PM
0 Comments
Daily Search Forum Recap: May 29, 2019 http://bit.ly/2I8XuDw Here is a recap of what happened in the search forums today, through the eyes of the Search Engine Roundtable and other search forums on the web. Search Engine Roundtable Stories:
Other Great Search Forum Threads:
Search Engine Land Stories:Other Great Search Stories:Analytics Industry & Business Links & Promotion Building Local & Maps Mobile & Voice SEO PPC Search Features SEO via Search Engine Roundtable http://bit.ly/1sYxUD0 May 29, 2019 at 03:00PM
https://selnd.com/2qU1XVp
Google sunsetting two bidding strategies in June https://selnd.com/2XewHfA Google will retire the Target Search Page Location and Target Outranking Share automated bidding strategies at the end of next month. Instead, advertisers will be encouraged to use Target Impression Share, which encompasses impression share for certain page position targets. When is the changing happening? The strategies will no longer be available for new campaigns starting in late June. At some point later this year, any existing campaigns still using them will get migrated to the Target Impression Share strategy, based on previous target positions and historical impression share. 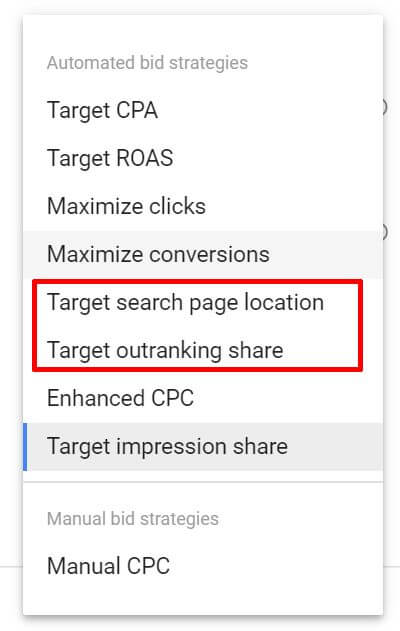
Target search page location and Target outranking share are getting phased out. What is Target impression share? Google introduced Target Impression Share to its portfolio of automated bidding strategies in November. You can set one of three placement options for this strategy: absolute top of the page (position one), top of the page (above the organic results), or anywhere on the page (above or below the organic results). Why we should care. This shift is in line with Google’s introduction of new ad position metrics that focus on top and absolute top impressions and impression share and plan to eliminate average position reporting later this year. Google suggests using the new impression share metrics when aiming to show your ads in particular locations on the page. It appears you’ll no longer be able to specifically aim to outrank a certain competitor. With Target outranking share, you could identify a competitor’s domain you wanted to aim to show above for a percentage of auctions. (However, it adjusts bids at the keyword level, not just for each auction in which you’re up against your nemesis.) About The AuthorGinny Marvin is Third Door Media's Editor-in-Chief, managing day-to-day editorial operations across all of our publications. Ginny writes about paid online marketing topics including paid search, paid social, display and retargeting for Search Engine Land, Marketing Land and MarTech Today. With more than 15 years of marketing experience, she has held both in-house and agency management positions. She can be found on Twitter as @ginnymarvin. SEO via Search Engine Land https://selnd.com/1BDlNnc May 29, 2019 at 02:03PM
http://bit.ly/30RMHX7
The Case For Pin-point Local Tracking http://bit.ly/2EBvQyj Posted by TheMozTeam Not so long ago, tracking a “United States” SERP could give you an accurate depiction of what a searcher would see, regardless of where in the country they were. Now, unless a searcher is actively hiding their whereabouts, Google always knows where they are and serves results that are heavily influenced by their precise surroundings. In other words, the “national” or “market” level SERP is dead. Long live the “precise location” SERP. Of course, even though we know this to be true, we wouldn’t be us if we didn’t validate with a little (a lot of) data — when it comes time to set up your keyword tracking strategy, we want you to care as much about location as Google does. Setting up the SERP comparisonsSince proper keyword segmentation is essential to making sense of your SERP data (and more than one data point is always preferable when proving points), we divvied up our queries into two different categories:
Then came the tracking. We took each group of keywords, stuffed them into STAT, and tracked them in the centre of specific Portland and New York City ZIP codes, as well as in the US, English-speaking market as a whole. So, for example, one SERP is located to “10038 New York, NY” and the other is only located as far as “US-en.” Once we’d gathered all our SERPs (just over 600,000 of them), we did a bunch of side-by-side comparisons. We went keyword by keyword and looked at whether search results were present on both the ZIP code and market-level SERPs, and then if they appeared in the same order — is it here? Is it there? Are they both in rank four? The answer to all of the above is: Yes, yes, and yes, okay, similar. But the biggest question on our minds: Are market-level SERPs accurate enough to trust? 
General intent keywordsDiving into our general intent keywords first, we were surprised to find a somewhat high similarity between ZIP code and market-level SERPs. For starters, they shared 83 percent of their top 20 organic URLs. Of course, while this is higher than we expected, it still means that if we track our keywords without putting a searcher somewhere on the map, we kiss 17 percent of real-life search results goodbye, which is a lot. What important insights might we lose out on — are we ranking and don’t know it? Are we letting a competitor sneak up on us?
Looking at whether or not any of those results showed up in the same spot from one SERP to the next, things got even more concerning. Only 28 percent of organic results appeared in the same ranking position on both the local and national SERPs. So, even if we decide that doing without 17 percent of the results that our searchers see is fine by us, we can’t depend on the rank of the results to be accurate. Moving our attention over to SERP features, we found that only 70 percent appeared on both ZIP code and market-level SERPs, which is less than the organic results. Local packs are a good example of just how much you can miss. 31 percent of Portland’s SERPs and 27 percent of NYC’s returned a local pack, whereas only 12 percent of national SERPs produced one. So, even though these keywords don’t necessarily require a physical location, when Google knows that there’s a real searcher standing in a real spot, it will err on the side of local intent and adjust its results accordingly. As for the similarity of SERP feature rankings, they were only marginally more consistent than organic results with 33 percent appearing in the same position from SERP to SERP — hardly enough to make up for the increase in incorrect results. Local intent keywordsNext, it was time to look at our keywords with explicit local intent — how were they faring? The answer was: worse. Much, much worse. Remember how we could count on about 83 percent similarity for our general intent keywords? Here, national and ZIP code SERPs were only 32 percent similar when we compared the organic results on each.
And just like before, similarity took a big hit when it comes to SERP features. Market and ZIP code-level SERPs only share around 22 percent of SERP features, and just over nine percent showed up in the same rank. Think about something like the jobs result type from Google’s perspective, which is very specifically meant for hyper-local audiences. If you type [jobs] into Google (because this SEO business is just too much) and it doesn’t know where you are, what’s a search engine to do? Not give you accurate local job listings, that’s what.
Key findings and takeawaysSo, what does all of this mean?
To sum: you need to track hyper-locally if you want to nab accurate results. After all, one SERP that searchers actually see in the hand is worth two make-believe market-level SERPs in the bush. Want a detailed walkthrough of STAT? Say hello (don’t be shy) and request a demo. Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read! SEO via SEOmoz Blog https://moz.com/blog May 29, 2019 at 01:27PM
http://bit.ly/2woBgYU
Google Ads is Removing Two Bidding Strategies in June via @MattGSouthern http://bit.ly/2YPlH8K  Google is planning to remove the ‘Target Search Page Location’ and ‘Target Outranking Share’ bid strategies in late June. With the capabilities of Target Impression Share, introduced last November, Google has decided to no longer offer the above-mentioned bid strategies. Target Impression Share is a smart bidding strategy which automatically sets bids according to where the ad will show up. Advertisers can set bids to have their ads show up at the absolute top of the page, anywhere in the top section of the page, or anywhere on the search results page.
Campaigns using Target Search Page Location or Target Outranking Share bid strategies will be automatically migrated to Target Impression Share. After migrating to Target Impression share, campaigns will be automatically optimized based on previous target locations and historical impression share. SEO via Search Engine Journal http://bit.ly/1QNKwvh May 29, 2019 at 12:06PM
http://bit.ly/2Mg1mbu
Google Updates Guidelines on Using ‘How-to’ Structured Data via @MattGSouthern http://bit.ly/2X85gnD  Google has updated its help document on using ‘how-to’ structured data with new guidelines about things people should avoid doing. How-to structured data is a type of markup which communicates to Google that a piece of content is a how-to article. Using how-to markup makes a page eligible to appear in search as a rich result. Lizzy Harvey, a technical writer at Google, sent out a tweet yesterday notifying everyone about the updates. She also updated the mobile-first indexing document to align with yesterday’s announcement. Here’s a summary of what has been added to the document. Marking up steps
Unique images for each step
Images must be visible
One set of structured data per page So if you have a how-to guide with multiple sets of instructions, it may be best to separate them into several pages if you plan on using how-to markup. See the full guide here. SEO via Search Engine Journal http://bit.ly/1QNKwvh May 29, 2019 at 10:52AM
http://bit.ly/2Xe8NRe
How to Use Archived Versions of Websites for SEO Troubleshooting via @5le http://bit.ly/2Qw6Z3A In 2001, a nonprofit named the Internet Archive launched a new tool called the Wayback Machine on the URL: archive.org. The mission of the Internet Archive was to build a digital library of the Internet’s history, much the same way paper copies of newspapers are saved in perpetuity. Because webpages are constantly changing, the Wayback Machine crawlers frequently visit and cache pages for the archive. Their goal was to make this content available for future generations of researchers, historians, and scholars. But this data is just as valuable to marketers and SEO professionals. Whenever I am working on a project that involves a steep change in traffic either for my core site or a competitors, one of the first places I will look the cached pages before and after the changes in traffic. Even if you aren’t doing forensic analysis on a site, just having access to a site’s changelog can be a valuable tool. You can find old content or even recall a promotion that was run in the previous year. Troubleshooting with the Wayback MachineMuch like looking at a live website, the cached pages will have all the information available that might explain a shift in traffic. The entire website, with all HTML included, is contained within the cache, which makes it fairly simple to identify obvious structural or technical changes. In comparing the differences between a before and after image of my site or a competitor’s, I look for issues with:
Here are the steps to use the Wayback Machine for troubleshooting. 1. Put your URL into the search box of Archive.orgThis does not need to be a homepage. It can be any URL on the site. 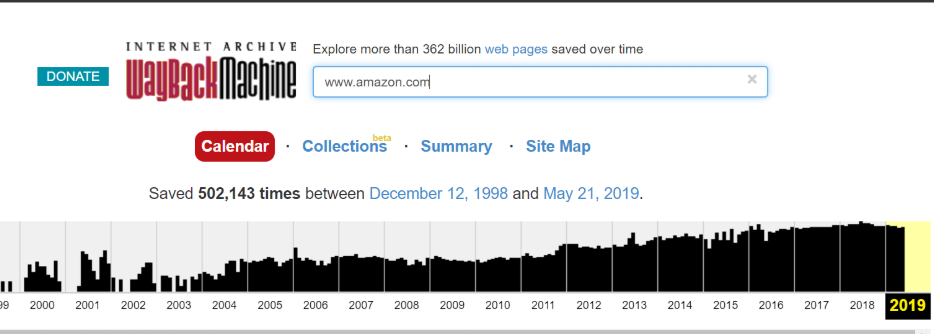 2. Choose a date where you believe the code may have changedNote the color coding of the dates:
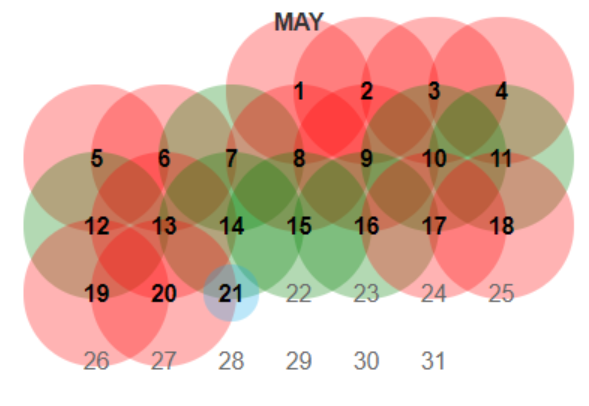 You may have to continue picking dates and then digging through each version until you find something interesting worth looking at further. For larger sites, you will find that homepages are cached multiple times per day while other sites will only be cached a few times per year 3. The cached page from archive.org will load in your browser like any website except that it will have a header from Archive.orgLook for obvious changes in structure and content that may have lead to a change in search visibility. 4. Open the source code of the page and search for:
5. Compare anything that is different from the current site and analyze causal or correlative relationshipsNo detail is too small to be investigated. Look at things like cross-links, words used on pages, and even for evidence that a site may have been hacked during a particular time period. You should even look at the specific language in any calls to action as a change here might impact conversions even if traffic now is higher than the time of the Wayback Machine’s cache. Robots File TroubleshootingThe Wayback Machine even retains snapshots of robots.txt files so if there was a change in crawling permissions the evidence is readily available. This feature has been amazingly useful for me when sites seem to have dropped out of the index mysteriously with no obvious penalty, spam attack, or a presently visible issue with a robots.txt file. To find the robots file history just drop the robots URL into the search box like this  After that choose a date and then do a diff analysis between the current robots file. There are a number of free tools online which allow for comparisons between two different sets of text. Backlink ResearchAn additional less obvious use case for the Wayback Machine is to identify how competitors may have built backlinks in the past. Using a tool like Ahrefs I have looked at the “lost” links of a website and then put them into the Wayback Machine to see how they used to link to a target website. A natural link shouldn’t really get “lost” and this is a great way to see why the links might have disappeared. Gray Hat UsesAside from these incredibly useful ways to use the Wayback Machine to troubleshoot SEO issues, there are also some seedier ways that some use this data. For those that are building private blog networks (PBNs) for backlink purposes, the archived site is a great way to restore the content of a recently purchased expired domain. The restored site is then filled with links to other sites in the network. AffiliatesOne other way, again from the darker side of things, that people have used this restored content is to turn it into an affiliate site for that category. For example, if someone bought an expired domain for a bank, they would restore the content and then place CTAs all over the site to fill out a mortgage form. The customer might think they were getting in touch with a bank. However, in reality, their contact info is being auctioned off to a variety of mortgage brokers. Not to end on a dark note, there is one final amazing way to use the Wayback Machine and it is the one intended by the creators of the site. This is the archive of everything on the web, and if someone was researching Amazon’s atmospheric growth over the last two decades through the progression of their website, this is where they would find an image of what Amazon’s early and every subsequent homepage looked like. 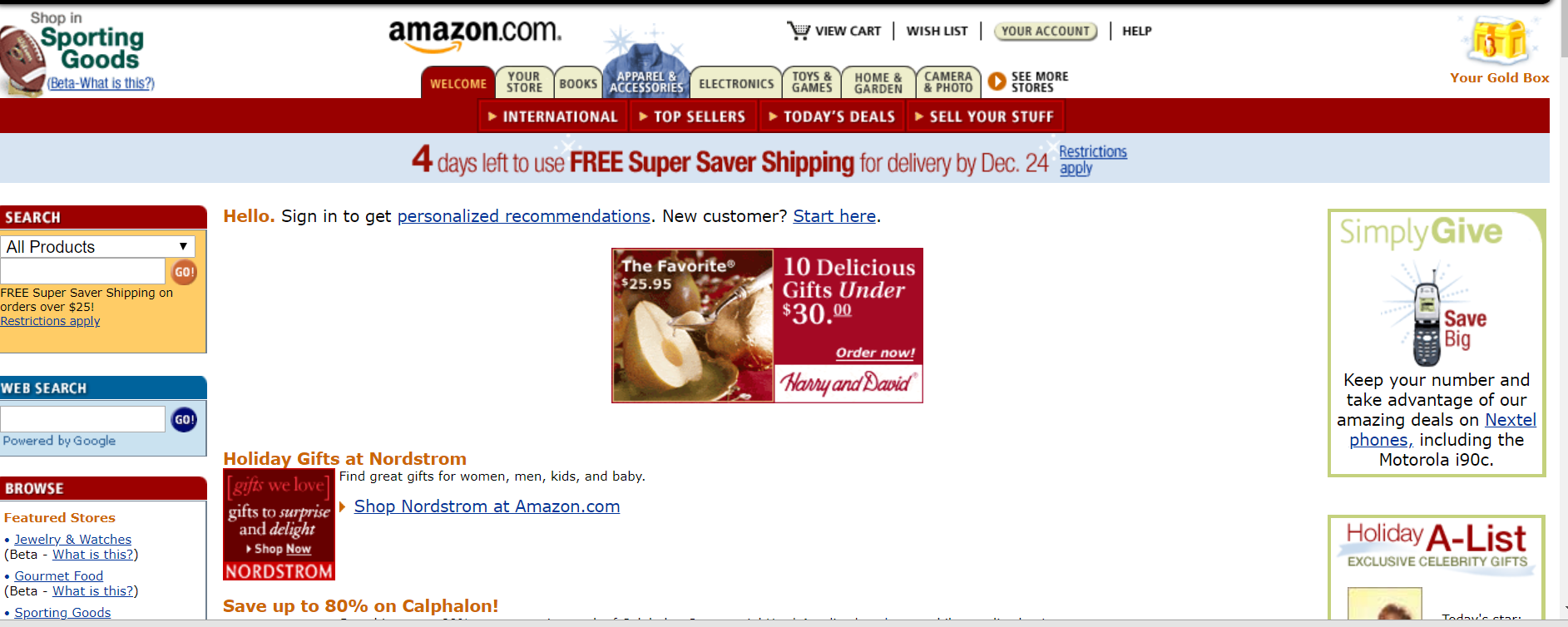 Shady use cases aside, the Wayback Machine is one of the best free tools you can have in your digital marketing arsenal. There is simply no other tool that has 18 years of history of nearly every website in the world. More Resources: Image Credits All screenshots taken by author, May 2019 SEO via Search Engine Journal http://bit.ly/1QNKwvh May 29, 2019 at 09:45AM
https://selnd.com/2JJJ14j
How to run Screaming Frog SEO Spider in the cloud in 2019 https://selnd.com/2QyEdiF Advanced technical SEO is not without its challenges, but luckily there are many tools in the market we can use. And by combining some of these tools not only can we address the challenges we face, we can create new solutions and take our SEO to the next level. In this guide I will be combining three distinct tools and utilize the power of a major cloud provider (Google Cloud), with a leading open source operating system and software (Ubuntu) and a crawl analysis tool (Screaming Frog SEO Spider). Examples of solutions this powerful combination can bring to the table are:
Combined with SEO expertise and a deep understanding of data this and so much more can be achieved. Both Google Cloud and Screaming Frog have further improved a lot in the last few years and so here is the updated, much shorter and easier guide to run one or multiple instances of Screaming Frog SEO Spider parallel in the Google Cloud or on your own Virtual Private Server (VPS). 
Quick startAssuming you already know how to use Linux and have a remote Ubuntu 18.04 LTS instance with enough resources running somewhere, e.g. Google Cloud, and you just want to download, install and/or update Screaming Frog SEO Spider on the remote instance in a jiffy then you can skip most of this guide by just logging into the remote instance and issue the following one-line command in the terminal on the remote instance:
If this does not work, or to better understand how to setup the remote instance, transfer data, schedule crawls and keeping your crawl running when you are not logged into the remote instance, continue reading. DependenciesBefore this guide continues, there are a few points that need to be addressed first. First, the commands in this guide are written as if your primary local operating system is a Linux distribution. However, most of the commands work locally the same with maybe minor tweaks on Windows and/or macOS. In case of doubt, or if you want to install Linux locally when you are on Windows, you can install different versions of Linux for free from the official Windows Store, for example Ubuntu 18.04 LTS. It is very useful if you have some experience and knowledge on how to access your terminal/command line interface on your operating system. Second, you will need a Google Cloud account, enable billing on this account, create a Google Cloud project and install the gcloud command line tool locally on your Linux, macOS or Windows operating system. If you created a new Google Cloud project for this guide, it can help to visit the Google Compute Engine overview page of your project in a web browser to automatically enable all necessary APIs to perform the tasks below. Be mindful, running Screaming Frog SEO Spider in the cloud will cost money – use budget alerts to notify you when cost arise above expectations. Alternatively, if you have a Ubuntu 18.04 LTS based VPS somewhere or an Amazon AWS or Azure account you can use this too for this guide. The commands for creating an instance are different and depend on the cloud provider you are using, but the overall principles are the same. To better enable you to use this guide independent of any cloud provider I included generic how to connect instructions below to get you started. Third, you will need to have a valid and active Screaming Frog SEO Spider license. Lastly, and this is optional, if you have a specific crawl configuration you want to use with Screaming Frog SEO Spider you need to install Screaming Frog SEO Spider locally, configure it and export the configuration settings as a new file, hereafter referred to as:
Assuming the points above are all checked, you can proceed and set up one or multiple separate instances to crawl with Screaming Frog SEO Spider remotely and parallel in the cloud using this guide. Setting up the Google Compute Engine instancesFirst, go to the terminal/command line interface (hereafter referred to as terminal) on your local computer and navigate to the folder you want to work from (e.g. store all the crawls). Next, identify the project id of your Google Cloud project and choose a Google Compute Engine zone. You will need this going forward. Issue the following command in the terminal to create a remote Google Compute Engine instance in the Google Cloud:
Replace <NAME> with any name, for the purpose of this guide I will go with “instance1”. Replace <PROJECT_ID> with the project id from your Google Cloud project, for the purpose of this guide I will go with “gce-sf”. And replace <ZONE> with the chosen zone, for the purpose of this guide I will go with “us-central1-a”. Now the command looks like:
This will create a remote instance on Google Compute Engine, with a 200GB SSD hard disk, 4 vCPUs, 15GB RAM and using Ubuntu 18.04 LTS minimal as operating system. If you like you can change the size for the hard disk or replace the SSD with a classic hard disk (at least 60GB) or change the number of CPUs and RAM by choosing another machine type. 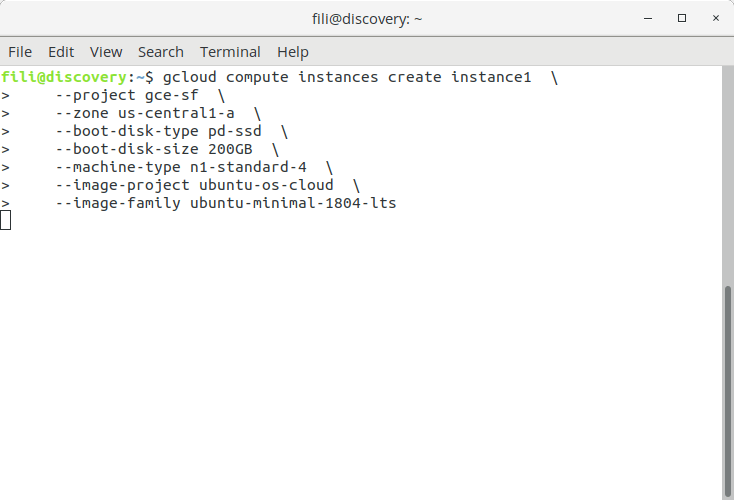
Creating a new instance on Google Compute Engine using the gcloud command line tool. Copying configuration settings (optional)Now that the remote instance is created, now is a good time to transfer the Screaming Frog SEO Spider configuration file locally stored on our computer to the remote instance. Issue the following command in the terminal on the local computer:
Again replace <NAME>, <PROJECT_ID> and <ZONE> with the same values as the previous step. Next also replace <FILENAME> with the name of the configuration file loclaly, which for the purpose of this guide is named “default.seospiderconfig”. Now the command looks like:
You can skip this step if you are just testing this guide or if you want to use the default Screaming Frog SEO Spider configuration without any changes. Command for transferring the Screaming Frog SEO Spider config file to Google Compute Engine instance. Connect to the remote instanceNow that our remote instance is running, connect to it and configure it for our Screaming Frog SEO Spider installation. Issue the following command in the terminal on your local computer:
Again replace <NAME>, <PROJECT_ID> and <ZONE> with the same values as in the previous steps. Now the command looks like:
This is how you reconnect to the remote instance whenever you are disconnected. 
Command for connecting to the Google Compute Engine instance. Alternative VPS or cloud hosting (AWS/Azure)The steps above are specific for Google Cloud as they utilize the Google Cloud command line tool gcloud. If you like to use another cloud provider such as Amazon AWS or Microsoft Azure, you can use their command line tools and documentation to set up your instances. If your plan to use a different VPS that can work just as fine. Issue the following command in the terminal to make a secure connection to the VPS:
Replace <USERNAME> and <IP_ADDRESS_OR_HOSTNAME> with the settings of the VPS. Now the command looks like:
And issue the following command in the terminal to copy the configuration file to the VPS:
Replace <CONFIG_FILE>, <USERNAME> and <IP_ADDRESS_OR_HOSTNAME> based on the name of the config file and the settings of your VPS. Now the command looks like:
Just make sure that for the purpose of this guide and the installation script the following requirements are met:
Connect to the remote instance and let’s continue to set up Screaming Frog SEO Spider. Installing Screaming Frog SEO Spider on the remote instanceNow that you are connected in the previous steps to the remote instance in the terminal, the next step is to download and run the installation script. My previous guide was approximately 6 thousand words, most of which were dedicated to installing the software and setting up a graphic interface to manage the remote Screaming Frog SEO Spider instance. In this guide most of that is replaced with just one line which does all the heavy lifting for you, however for this reason it is important to meet the requirements listed above or the software installation and configuration may fail. To download and run the installation script issue the following command in the terminal on the remote instance:
Wait for about 5 minutes (sometimes it may take up to 10 minutes) until all installation steps have completed and you see the success message. The script will start by asking you for:
If you have any problems, rerun the command. 
Command for installing Screaming Frog SEO Spider on Google Compute Engine (Google Cloud). For the purpose of this guide, let’s also create a subdirectory “crawl-data” in the home folder of the current user on the remote instance to save all the crawl data into, issue the following command:
Using tmux on the remote instanceNow that Screaming Frog SEO Spider is installed, let’s run it on the remote instance from the terminal. To make sure the loss of the connection to the remote instance doesn’t stop a crawl it is prudent to issue the command to run Screaming Frog SEO Spider independently from the connection to the remote instance. The installation script also installed a widely used command line tool for this purpose, called tmux. You can find guides and documentation to become a tmux wizard here, here and here. To start tmux issue the following command in the terminal on the remote instance:
This creates a terminal session independent from your connection to the remote instance. Now if you want to disconnect from this session, you can issue the following command to detach from within the tmux terminal session:
Or, when for example Screaming Frog SEO Spider is crawling, type on the keyboard Ctrl-b and then the letter d. If you want to reconnect to the tmux terminal session, for example when you log into the remote instance a few hours later again, issue the following command to connect to the tmux terminal session:
The zero in the command above refers to the first active tmux session. There may be more, especially if you accidentally ran the command tmux several times without using “attach” or if you run multiple Screaming Frog SEO Spider crawls on the same remote instance – yes, this is very easy to do with tmux but RAM, SWAP and CPU may be an issue. You can find out all active tmux sessions with issuing the following command:
And then open (using “tmux attach -t <NUMBER>”) each tmux terminal session, and then disconnect (“tmux detach”), to see the status what tmux is doing in each terminal session. Running Screaming Frog SEO Spider on the remote instanceNow that you understand how to use tmux, open an unused tmux terminal session and issue the following command in the tmux terminal session on the remote instance:
This command is only for testing that Screaming Frog SEO Spider is set up and working as expected. To see the result of the test crawl, issue the following command:
If all went well, a new subfolder in the crawl-data folder has been created with a timestamp as its name. This folder contains the data saved from the crawl, in this case a sitemap.xml and a crawl.seospider file from Screaming Frog SEO Spider which allows us to load it in any other Screaming Frog SEO Spider instance on any other computer. 
Command for running Screaming Frog SEO Spider on Google Compute Engine (Google Cloud). You can configure your crawls to use the configuration file mentioned above or to crawl a dedicated list of URLs. To learn more about the command line options to run and configure Screaming Frog SEO Spider on the command line, check out the documentation and/or issue the following command in the terminal on the remote instance:
Downloading the crawl dataNow that the crawling has been tested, let’s make sure that the crawl data collected is not lost and can be used. There are several options to get access to the crawl data. For the purpose of this guide the crawl data is stored in a subdirectory, named by timestamp, in the directory crawl-data which is located in the home folder of the user, e.g.
Direct transferThe first option is to transfer the data from the remote instance to the local computer issuing the following command in the terminal on the local computer:
Again replace <NAME>, <PROJECT_ID> and <ZONE> with the same values as in the previous steps. Now the command looks like:
Alternatively if when using another cloud provider or a VPS, to transfer the files to the current working directory using a secure connection issue the following command in the terminal on the local computer:
Replace <DIRECTORY_NAME>, <USERNAME> and <IP_ADDRESS_OR_HOSTNAME> based on the name of the directory and the settings of your VPS. Now the command looks like:
Although, command line tools from other cloud providers may have different commands to accomplish the same. Store in the cloudThe second option is to back up the crawl data to the Google Cloud in a Google Cloud Storage bucket. To make this happen, create a new storage bucket by issuing the following command (in either the terminal on the local computer or remote instance):
Replace <PROJECT_ID> with the Google Cloud project id and use any name for the <BUCKET_NAME>. The bucket name can be any name, however many are unavailable so it may take a tries before you get one that works for you. Now the command looks like:
Transfer the whole directory with the crawl data, including all subdirectories, from the remote instance to the storage bucket by issuing the following command in the terminal on the remote instance:
Replace <DIRECTORY_NAME> with the directory to transfer from the remote instance to the storage bucket and the <BUCKET_NAME> with the name of the storage bucket. Now the command looks like:
Now that the data is safely backed up in a Google Cloud Storage bucket, it opens up a number of exciting opportunities for SEO. For example, if a sitemap export from the crawl is stored in the Google Cloud Storage bucket, you can also make this public so it can act as the daily generated XML Sitemap for your website and reference it from your robots.txt file. In addition, you can now also choose to utilize Google Bigquery to import the exported CSV reports from Screaming Frog SEO Spider and use Google Data Studio to display the data in meaningful graphs. This and more is possible now that the data is accessible in the cloud. Updating Screaming Frog SEO Spider on the remote instanceIf you want to update Screaming Frog SEO Spider or something went wrong during the installation and you want to try it again, just connect to the remote instance and issue the following command in the terminal on the remote instance:
When running the installation script again, Screaming Frog SEO Spider will be automatically updated to its latest release. Running multiple instancesYou can repeat the steps above to create as many instances you want, install Screaming Frog SEO Spider and to run multiple different crawls parallel to each other. For example, I often run multiple remote instances parallel at the same time, crawling different URLs. Scheduling repeat crawlsNow that the remote instance is running, it is possible to schedule regular crawls using cron. First decide how often the regular crawl needs to run? If you are unfamiliar with cron schedule expressions, try out this handy tool. For the purpose of this guide the scheduled crawl will run 1 minute after midnight and then every following 12 hours. To proceed cron needs be configured by issuing the following command in the terminal on the remote instance:
This will open a terminal editor nano which was also installed using the installation script above. Once inside the nano editor, add the following line to crontab:
For debugging purposes it is strongly recommended to keep the output of the crawl logged somewhere. The easiest way to do this is to store and append the runtime data into plain text file, which for the purpose of this guide is called:
Replace <COMMAND> and <LOG_FILE> with the actual command to run Screaming Frog SEO Spider (on one line). Now the line to add to crontab looks like:
This process can be repeated for transferring the crawl data to the Google Cloud Storage bucket on a regular basis by adding the following line to crontab:
This line copies the crawl-data directory in full to the storage bucket, 15 minutes before the next scheduled crawl starts. Assuming only the latest crawl needs to be transferred, the easiest way of accomplishing this is by automatically delete all past crawl data when configuring the scheduled transfer by adding the following line in crontab instead:
Adding the two lines, one for running the scheduled crawl and one for scheduled transfer and deletion is useful. However it is more efficient to combine these three separate commands into one line in cron, each dependent on successful completion of each other (in other words, if one fails the commands afterwards will not be executed), which looks like:
If this gets too complicated it is also possible to learn the amazing world of shell scripts, write your own shell script and put the separate commands in there and then execute the shell script using cron. To close and save the new cron job, use the keyboard shortcut Ctrl-X and confirm saving the new settings. To become a wizard in using cron, start here. 
Cron scheduling Screaming Frog SEO Spider on Google Compute Engine. Deleting the remote instances and storage bucketTo avoid accruing additional costs when you are not using the remote instance to crawl (so when you don’t have repeat crawls scheduled and you are done crawling), it is important to delete the instance. Keeping it running can be costly in the long term. To delete your instances, issue the following command in the terminal on your local computer:
Again replace <NAME>, <PROJECT_ID>, <ZONE> with the same values as in the previous steps. Now the command looks like:
To delete multiple instances in one-go, just add the different instance names to the command like this:
Warning: when you delete the remote instance, all data stored on the remote instance is also deleted and can not be recovered later. Be sure to transfer all data from the remote instances to your local computer or a Google Cloud Storage bucket before using delete-instances command. In addition, you can delete the Google Cloud Storage bucket by issuing the following command in the terminal:
Replace <BUCKET_NAME> with the chosen name for the bucket. Now the command looks like:
Final thoughtsI want to close on a cautionary note, and that is to keep an eye on the cost of the remote instances and data stored in your cloud bucket. Running Screaming Frog SEO Spider in the cloud does not need to cost much, but lose your eye on the ball and it can be costly. I also highly recommend reading the different documentation and manuals for the different programs mentioned in this guide, as you will find that many adaptations of the commands used in this guide are possible and may make more sense for your situation. Happy crawling! Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here. About The Author
Fili
is a renowned technical SEO expert, ex-Google engineer and was a senior technical lead in the Google Search Quality team. At SearchBrothershe offers SEO consulting services with SEO audits, SEO workshops and successfully recovers websites from Google penalties. Fili is also a frequent speaker at SMX and other online marketing events. SEO via Search Engine Land https://selnd.com/1BDlNnc May 29, 2019 at 08:42AM
https://selnd.com/2Wb5kq9
Bing turns 10: Why it’s been more disruptive than you think https://selnd.com/2ECwaN8 Ten years ago today, Microsoft launched Bing. A decade in, Bing’s evolution looks different depending on your perspective. After investing billions, Bing’s market share is still small, but Microsoft has stayed committed to search, used it to enhance its other products and has bigger plans ahead for its advertising business. A condensed history of Microsoft’s foray into searchIt’s Bing’s 10th birthday, but Microsoft’s foray into search engines began nearly 21 years ago when it used technology from Inktomi, Looksmart and AltaVista to power Bing’s ancestor MSN Search. MSN Search eventually became known as Live Search. By 2005, it was clear that Microsoft aspired to be a player in the search engine sector when it began using its own proprietary web crawler. Image search, however, would continue to be outsourced to a third party for another year — a far cry from the deep learning now used in Bing Image Search. Microsoft moved further away from third-party suppliers in 2006 by implementing its own image search algorithm and switching to its own ad service, then called MSN adCenter. The next year, the company made a number of changes that continue to impact how it operates today, including stripping the Windows branding from its search engine and appointing now-CEO Satya Nadella to lead its newly-formed Search and Ad Platform Group. Over the following years, a string of reorganizations, consolidations and discontinuations would lead to the rise of Microsoft’s modern search machine, Bing. Named after the sound “in our heads when we think about that moment of discovery and decision making — when you resolve those important tasks,” Bing officially replaced Live Search on June 3, 2009. Bing’s new groove under NadellaLooking back at what might’ve been helps us get a better appreciation for just how far Microsoft and Bing have come. Nokia’s then-CEO Stephen Elop, who was reportedly open to selling Bing, was another candidate in the running to succeed Microsoft CEO Steve Ballmer in 2014. Nadella, on the other hand, had nearly two decades at Microsoft, including in search, and a background in engineering, computer science and business under his belt. Those experiences allowed him to recognize Bing’s potential value to Microsoft’s overall business strategy. And, in case you were curious, Bing became profitable just a year and a half after Nadella became CEO. Under Nadella’s Microsoft, Bing became the vehicle that drove advancements in AI and machine learning and the “intelligent fabric” woven into Windows 10, Xbox, Azure, Office 365, Cortana and other Microsoft products. Microsoft also acquired LinkedIn and GitHub and has begun finding ways to connect the dots between Bing and those platforms. Although GitHub’s benefits for search marketers (and Microsoft, itself) is yet to be determined, it is opening up to more interaction with the developer and researcher communities through initiatives like making one of Bing’s vector search algorithms available as an open-source GitHub project. To the beat of a different drumTo compete with Google, Bing has had to walk a fine line between feeling familiar to users while offering them reasons to switch. It vied for market share with expensive marketing campaigns — Bing It On, for example — early on and continues to run what’s now called the Microsoft Rewards program. It has also been a first-mover at times. Its disavow tool for SEOs came out several months ahead of Google’s version. More recently, it has rolled out “intelligent search” results and news spotlights to give users more context in the search results. Bing’s API has become a valuable tool for search development and SEOs. “While there are certainly many ways in which Bing helped advance our industry (Bing Webmaster Tools being one of them), I think the open access to their API has had an even more profound effect on the search ecosystem in general,” said Russ Jones, principal search scientist for Moz. “Without Bing, there would be no viable privacy-centric API. Of all the things Google has delivered on, they have never (nor will they ever) provide a search engine that fully respects the privacy of their users. But Bing’s web search API has opened the door to entrants like DuckDuckGo, which can build a safe, private experience for users on top of a world-class search engine, without using privacy-invasive techniques to fund the business. It’s hard to express how important Bing has been in this regard.” Microsoft’s ownership of GitHub and recent algorithm open sourcing are bridges to the researcher and developer communities. These moves may have strong business cases behind them, but the company doesn’t seem to mind that “a rising tide lifts all boats.” “It’s hard to overstate the value of Bing’s API for research purposes. There are so many applications that require bulk or real-time SERPs which could not exist without a proper search engine with API access,” Jones added. “As Google has steadily rolled back access to its SERPs via programmatic methods, Bing has continued to offer an accessible API. This has single-handedly powered NLP [natural language processing] research, especially real-time applications, at scales that would be fundamentally unattainable if people were forced to scrape.” Some might dismiss these as moral victories, but that downplays the amount of thought and development that has gone into Bing’s search experience and marketer offerings — offerings that provide an economical alternative or extension of campaigns beyond Google. Optimizing for Bing still isn’t a thingDespite offering numerous unique SERP features, most search market share estimates put Bing in a distance second place. For SEOs this means it often doesn’t get a lot of attention. “I have found the most valuable thing about Bing to be to help confirm client ‘shot-in-the-foot’ SEO issues,” said Andrew Shotland, CEO and founder of LocalSEOGuide.com, explaining that he uses Bing to check whether organic traffic dips can be attributed to a Google algorithm update or other SEO problems. Bing’s place in Shotland’s toolbox isn’t unique to him either, as Bing’s relatively small share of the search market perpetuates its image as an ancillary platform for marketers — a luxury for brands and companies with enough resources to cover their bases. “The data we get from Bing is valuable,” admitted Dana DiTomaso, president and partner at Kick Point, “but with such a limited market share, it’s hard to draw conclusions or extrapolate this out to include Google users as well.” For all its merits, Bing has yet to shake off bridesmaid syndrome for the majority of searchers and the brands and marketers that follow them. “Despite a lot of success, and Bing winning on many dimensions in blind tests, it has taken significant focus and grit for us to earn consumer use incrementally over 100 months of consecutive growth,” Steve Sirich, GM of Microsoft Advertising Marketing, told Search Engine Land when asked about the ways in which Bing has struggled to keep up with expectations. “There has not been an easy step-change but demonstrates the focus and commitment we have to this industry,” he added, pointing to Bing’s doubling of its PC search market share since launch and its growth into Microsoft’s fifth largest business, accounting for roughly $7 billion from advertising. From playing catch up to developing exclusive ad featuresMicrosoft is making a huge bet in advertising and on the advertising group, executives told agency representatives at last month’s Microsoft Advertising Partner Summit in Seattle last month. For most of its existence, Bing Ads was defined almost as much by its relationship with Yahoo as anything else. The search partnership between Microsoft and Yahoo was often strained and convoluted for advertisers to navigate (you can find our archives on this history here). Yahoo is now a shadow of its former self and under the umbrella of Verizon Media. In January, Microsoft Advertising became the exclusive search advertising platform for Verizon Media properties, including Yahoo and AOL. Over the years, Bing gained momentum internally at Microsoft. And In 2014, Microsoft began articulating its roadmap for Bing to grow market share through integrations with Microsoft properties — from Office to Xbox to the ill-fated Windows Phones — as well as external integrations such as with iOS, Twitter, Facebook and Amazon. “We think of Bing less and less as a destination portal. We’re trying to put search where users are,” then director of search Stephan Weitz told Search Engine Land. After doubling down on being a search-only advertising platform for a period — that differentiated it from Google AdWords at the time, but audience targeting was starting to take off and Microsoft hadn’t bought LinkedIn, yet — Microsoft Advertising is now taking a wider perspective on the capabilities it can offer advertisers. “Bing and Microsoft Advertising are challenger brands—but they’re challenger brands that are part of one of the the top three largest companies in the world,” said Jeremy Hull, SVP of Innovation at iProspect. “What I find most exciting about Microsoft Advertising is that they’re once again moving away from simply providing parity with other solutions. They’re building innovative differentiators that competitors can’t touch, such as integration with LinkedIn for incredibly powerful B2B targeting.” That broader charter is reflected in last month’s rebranding as Microsoft Advertising. The consumer-facing search engine is still Bing, but the new name reflects a few things about where the advertising side of the business is heading. “We are redefining the soul of what Bing stands for,” Rik van der Kooi CVP, Microsoft Advertising, said at Microsoft Advertising Partner Summit. “We will be hearing more about the differentiation on what we want Bing to be in addition to being a great search solution.” The Microsoft Audience Network (MSAN), launched last year, combining Bing search signals, Microsoft’s AI assets and its audience graph, which includes LinkedIn for advertising Microsoft properties such as MSN, Outlook.com and the Edge browser. Bing’s integration into multiple products continues, and it’s become a foundational piece of Microsoft’s AI efforts. It continues to focus on market share growth through partnerships. For example, in a deal with Amazon’s Silk browser, Bing powers search for more than 10,000 partners, said van der Kooi. These factors have afforded the search and advertising groups more flexibility in the features and capabilities they can develop and offer. AI capabilities have given them the “right to innovate,“ as David Pann, general manager of global search advertising at Microsoft, put it last fall at SMX East, Rather than fast-following Google Ads to keep up parity, the “whole idea of parroting versus innovating is flip-flopped,” he said. While it still lags in market share, it has won over many advertisers. “I was around for the launch of Bing in 2009. It was an exciting time for advertisers — we could see that Microsoft was serious about search ads, and were optimistic about the future,” said Melissa Mackey, search supervisor at Gyro. “Today, Microsoft Advertising has carved out a permanent place at the table when it comes to paid search. Advertisers often see better results from Microsoft Ads’ unique audience. Now, with their partnership with LinkedIn, advertisers can get audience targeting options that aren’t available with any other search provider. Microsoft Ads continues to deliver innovative solutions for advertisers, while maintaining the focus on the customer that has made them a favorite in the PPC industry.” The company is also focusing deeply on a few core verticals to develop specialized solutions — such as a co-bidding pilot for retailers and brands — and working with agencies to help them deploy Microsoft technology. A program called One Microsoft for marketers incorporates advertising, Azure machine learning and other Microsoft technologies to create custom experiences. Microsoft’s mission accomplished?Success is measured on relative terms. Before passing judgment on how far Bing has come, keep in mind that it is one of Microsoft’s many products — albeit a very important one — and that it doesn’t operate with the same resources as Google. “We have demonstrated that there can be a competitive player in the industry that is a viable alternative to the incumbent for consumers, publishers and advertisers,” Sirich asserted, concluding that, “This has spurred innovation and helped to keep pricing in check, which has benefited the entire industry.” Advertisers continue to root for competition and innovation. “It’s my hope that Microsoft continues to lean into these differentiators,” said Hull, “which will continue to shift the perception of their advertising offering from being seen as just an extension of a channel strategy and into a completely separate solution that delivers compelling results for a variety of brands and verticals.” About The AuthorGeorge Nguyen is an Associate Editor at Third Door Media. His background is in content marketing, journalism, and storytelling. SEO via Search Engine Land https://selnd.com/1BDlNnc May 28, 2019 at 01:05PM
http://bit.ly/2I0qRYO
People Are Using Instagram More, Facebook and Snapchat Less via @MattGSouthern http://bit.ly/2MbwYil Time spent on Instagram is expected to grow this year, while Facebook will not recover from last year’s drop in engagement. In a new report from eMarketer, estimates for time spent on Facebook in 2019 has been reduced compared to the figures released late last year. Instagram, on the other hand, is expected to grow its average daily time spent by users by one minute every year through 2021. eMarketer says average daily time spent on Snapchat has “plateaued.” Facebook engagement in declineAverage daily time spent on Facebook by US adult users fell by 3 minutes in 2018. eMarketer attributes this to Facebook discouraging passive consumption of content, namely videos. According to eMarketer’s updated estimates, Facebook users will spend an average of 38 minutes per day on the platform (on all devices), which is down 2 minutes from the previous forecast. 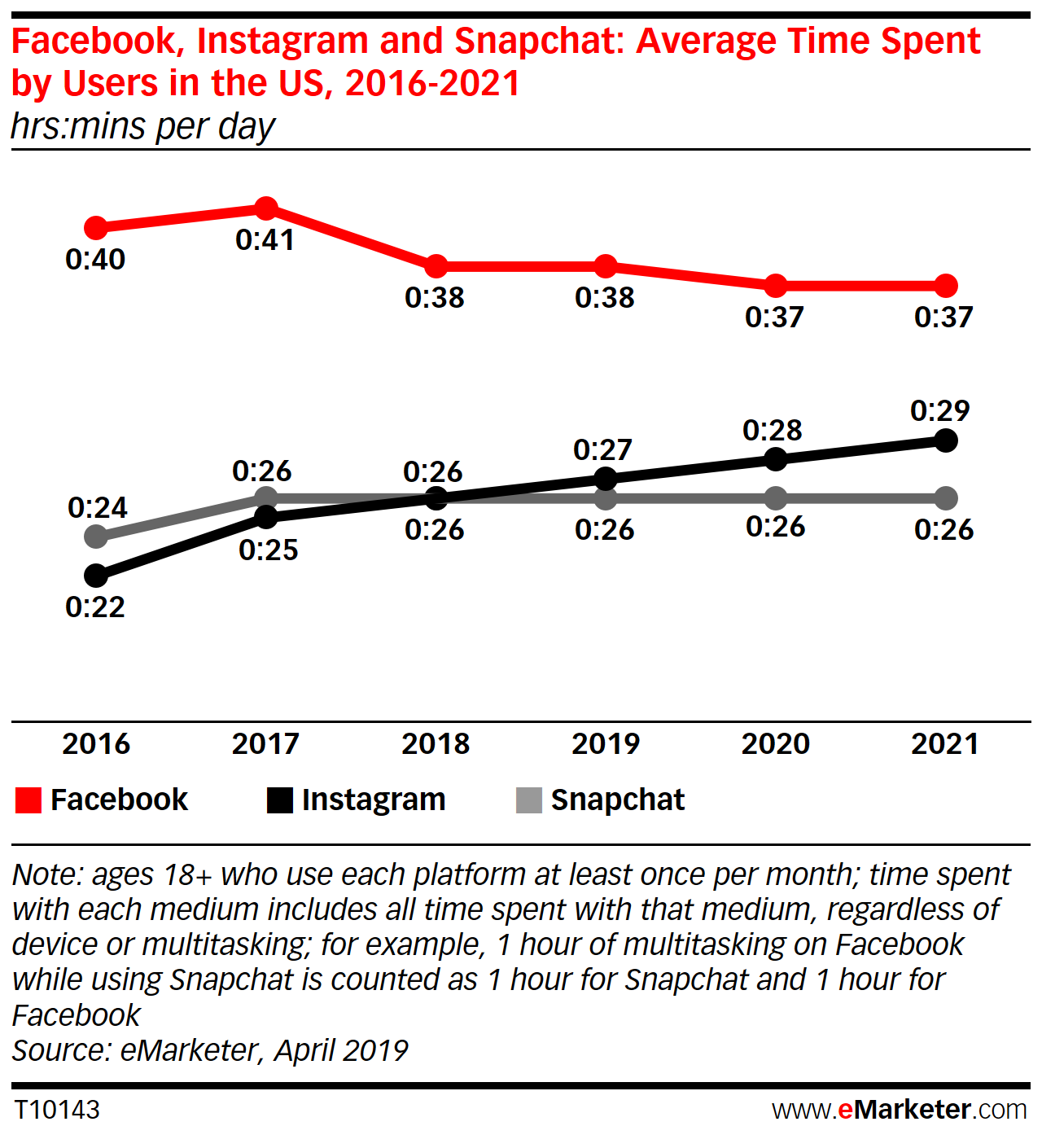 
Looking ahead to 2020, the average daily time on Facebook will drop to 37 minutes. eMarketer principal analyst, Debra Aho Williamson, speaks on this updated forecast:
Time will tell if Facebook makes any changes to address the fact that people are spending less time on its network. SEO via Search Engine Journal http://bit.ly/1QNKwvh May 28, 2019 at 11:57AM |
Categories
All
Archives
November 2020
|
 RSS Feed
RSS Feed
